
|
CRAFT: Video Diffusion for Bimanual Robot Data Generation
Jason Chen, I-Chun Arthur Liu, Gaurav Sukhatme, Daniel Seita
@inproceedings{chen2026craft,
title={{CRAFT: Video Diffusion for Bimanual Robot Data Generation}},
author={Jason Chen and I-Chun Arthur Liu and Gaurav Sukhatme and Daniel Seita},
booktitle={International Conference on Intelligent Robots and Systems (IROS)},
Year={2026}
}
IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2026.
|

|
Concurrent Prehensile and Nonprehensile Manipulation: A Practical Approach to Multi-Stage Dexterous Tasks
Hao Jiang, Yue Wu, Yue Wang, Gaurav Sukhatme, Daniel Seita
@inproceedings{jiang2026dexmulti,
title={{Concurrent Prehensile and Nonprehensile Manipulation: A Practical Approach to Multi-Stage Dexterous Tasks}},
author={Hao Jiang and Yue Wu and Yue Wang and Gaurav S. Sukhatme and Daniel Seita},
booktitle={International Conference on Intelligent Robots and Systems (IROS)},
Year={2026}
}
IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2026.
|

|
HANDFUL: Sequential Grasp-Conditioned Dexterous Manipulation with Resource Awareness
Ethan Foong*, Yunshuang Li*, Hao Jiang, Gaurav Sukhatme, Daniel Seita
@inproceedings{jiang2026dexmulti,
title={{HANDFUL: Sequential Grasp-Conditioned Dexterous Manipulation with Resource Awareness}},
author={Ethan Foong and Yunshuang Li and Hao Jiang and Gaurav S. Sukhatme and Daniel Seita},
booktitle={International Conference on Intelligent Robots and Systems (IROS)},
Year={2026}
}
IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2026.
|

|
ICLR: In-Context Imitation Learning with Visual Reasoning
Toan Nguyen, Weiduo Yuan, Songlin Wei, Hui Li, Daniel Seita†, Yue Wang†
@inproceedings{ngyuen2026_icil_iclr,
title={{ICLR: In-Context Imitation Learning with Visual Reasoning}},
author={Toan Nguyen and Weiduo Yuan and Songlin Wei and Hui Li and Daniel Seita and Yue Wang},
booktitle={International Conference on Intelligent Robots and Systems (IROS)},
Year={2026}
}
IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2026.
|

|
Red-Teaming Vision-Language-Action Models via Quality Diversity Prompt Generation for Robust Robot Policies
Siddharth Srikanth, Freddie Liang, Ya-Chuan Hsu, Varun Bhatt, Shihan Zhao, Henry Chen, Bryon Tjanaka, Minjune Hwang, Akanksha Saran, Daniel Seita†, Aaquib Tabrez†, Stefanos Nikolaidis†
@inproceedings{srikanth2026qdig,
title={{Red-Teaming Vision-Language-Action Models via Quality Diversity Prompt Generation for Robust Robot Policies}},
author={Siddharth Srikanth and Freddie Liang and Ya{-}Chuan Hsu and Varun Bhatt and Shihan Zhao and Henry Chen and Bryon Tjanaka and Minjune Hwang and Akanksha Saran and Daniel Seita and Aaquib Tabrez and Stefanos Nikolaidis},
booktitle={International Conference on Intelligent Robots and Systems (IROS)},
Year={2026}
}
IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2026.
|

|
PREFAIL: Identifying Precursors to Failures in Robotic Lift-and-Place Tasks to Improve Task Execution Performance
Zeyu Shangguan, Rajas Chitale, Rutvik Patel, Satyandra K. Gupta, Daniel Seita
@inproceedings{shangguan2026prefail,
title={{PREFAIL: Identifying Precursors to Failures in Robotic Lift-and-Place Tasks to Improve Task Execution Performance}},
author={Zeyu Shangguan and Rajas Chitale and Rutvik Patel and Satyandra K. Gupta and Daniel Seita},
booktitle={International Conference on Intelligent Robots and Systems (IROS)},
Year={2026}
}
IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2026.
|
|
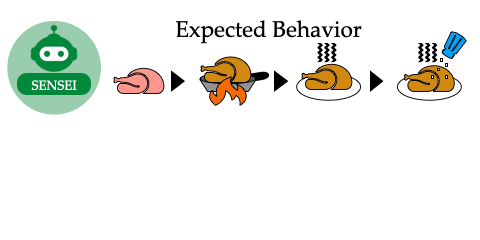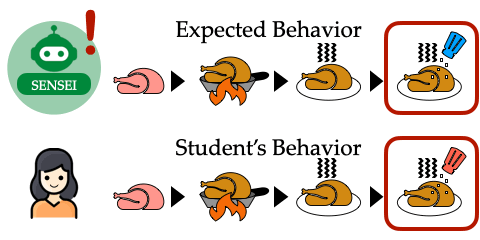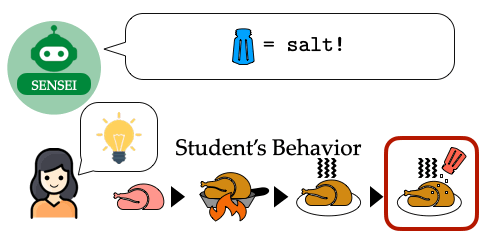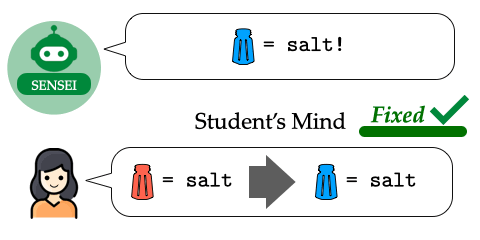
Fix the Mind, Not the Move: Interpretable AI Assistance via Knowledge-Gap Localization
Ayano Hiranaka*, Ya-Chuan Hsu*, Stefanos Nikolaidis, Erdem Bıyık†, Daniel Seita†
@inproceedings{hiranaka2026sensei,
title={{Fix the Mind, Not the Move: Interpretable AI Assistance via Knowledge-Gap Localization}},
author={Ayano Hiranaka and Ya-Chuan Hsu and Stefanos Nikolaidis and Erdem Bıyık and Daniel Seita},
booktitle={International Conference on Machine Learning (ICML)},
Year={2026}
}
International Conference on Machine Learning (ICML), 2026.
|

|
LAM: Language Articulated Object Modelers
Yipeng Gao, Yunhao Ge, Peilin Cai, Daniel Seita, Laurent Itti
@inproceedings{gao2026LAM,
title={{LAM: Language Articulated Object Modelers}},
author={Yipeng Gao and Yunhao Ge and Peilin Cai and Daniel Seita and Laurent Itti},
booktitle={Computer Vision and Pattern Recognition (CVPR)},
Year={2026}
}
Computer Vision and Pattern Recognition (CVPR), 2026.
|

|
ROPA: Synthetic Robot Pose Generation for RGB-D Bimanual Data Augmentation
Jason Chen, I-Chun Arthur Liu, Gaurav Sukhatme, Daniel Seita
@inproceedings{chen2026ropa,
title={{ROPA: Synthetic Robot Pose Generation for RGB-D Bimanual Data Augmentation}},
author={Jason Chen and I-Chun Arthur Liu and Gaurav Sukhatme and Daniel Seita},
booktitle={International Conference on Robotics and Automation (ICRA)},
Year={2026}
}
IEEE International Conference on Robotics and Automation (ICRA), 2026.
|

|
Learning Geometry-Aware Nonprehensile Pushing and Pulling with Dexterous Hands
Yunshuang Li, Yiyang Ling, Gaurav Sukhatme, Daniel Seita
@inproceedings{li2026nonprehensile,
title={{Learning Geometry-Aware Nonprehensile Pushing and Pulling with Dexterous Hands}},
author={Yunshuang Li and Yiyang Ling and Gaurav Sukhatme and Daniel Seita},
booktitle={International Conference on Robotics and Automation (ICRA)},
Year={2026}
}
IEEE International Conference on Robotics and Automation (ICRA), 2026.
|

|
IMPACT: Intelligent Motion Planning with Acceptable Contact Trajectories via Vision-Language Models
Yiyang Ling*, Karan Owalekar*, Oluwatobiloba Adesanya, Erdem Bıyık, Daniel Seita
@inproceedings{ling2026impact,
title={{IMPACT: Intelligent Motion Planning with Acceptable Contact Trajectories via Vision-Language Models}},
author={Yiyang Ling and Karan Owalekar and Oluwatobiloba Adesanya and Erdem Bıyık and Daniel Seita},
booktitle={International Conference on Robotics and Automation (ICRA)},
Year={2026}
}
IEEE International Conference on Robotics and Automation (ICRA), 2026.
|
|
V-MORALS: Visual Morse Graph-Aided Discovery of Regions of Attraction in a Learned Space
Faiz Aladin, Ashwin Balasubramanian, Lars Lindemann, Daniel Seita
@inproceedings{aladin2026vmorals,
title={{V-MORALS: Visual Morse Graph-Aided Discovery of Regions of Attraction in a Learned Space}},
author={Faiz Aladin and Ashwin Balasubramanian and Lars Lindemann and Daniel Seita},
booktitle={International Conference on Robotics and Automation (ICRA)},
Year={2026}
}
IEEE International Conference on Robotics and Automation (ICRA), 2026.
|

|
SCOOP'D: State-based Sim2Real Generative Policy for Generalizable Mixed-Liquid-Solid Scooping
Kuanning Wang, Yongchong Gu, Yuqian Fu, Zeyu Shangguan, Sicheng He, Xiangyang Xue, Yanwei Fu, Daniel Seita
@inproceedings{wang2026scooping,
title={{SCOOP'D: State-based Sim2Real Generative Policy for Generalizable Mixed-Liquid-Solid Scooping}},
author={Kuanning Wang and Yongchong Gu and Yuqian Fu and Zeyu Shangguan and Sicheng He and Xiangyang Xue and Yanwei Fu and Daniel Seita},
booktitle={International Conference on Robotics and Automation (ICRA)},
Year={2026}
}
IEEE International Conference on Robotics and Automation (ICRA), 2026.
|
|
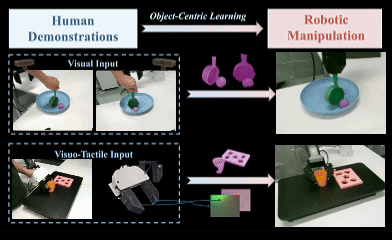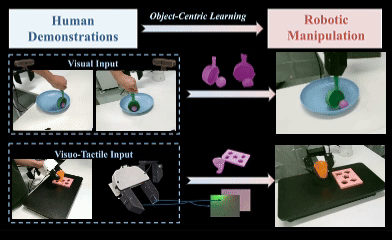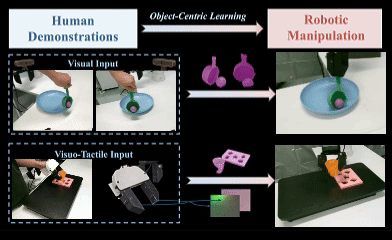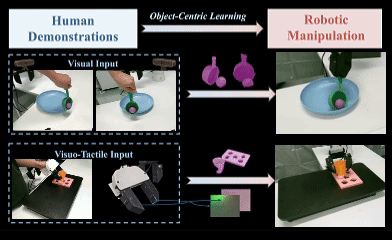
OCRA: Object-Centric Learning with 3D and Tactile Priors for Human-to-Robot Action Transfer
Kuanning Wang*, Ke Fan*, Yuqian Fu, Siyu Lin, Hu Luo, Daniel Seita, Yanwei Fu, Yu-Gang Jiang, Xiangyang Xue
@inproceedings{wang2026orca,
title={{OCRA: Object-Centric Learning with 3D and Tactile Priors for Human-to-Robot Action Transfer}},
author={Kuanning Wang and Ke Fan and Yuqian Fu and Siyu Lin and Hu Luo and Daniel Seita and Yanwei Fu and Yu{-}Gang Jiang and Xiangyang Xue},
booktitle={International Conference on Robotics and Automation (ICRA)},
Year={2026}
}
IEEE International Conference on Robotics and Automation (ICRA), 2026.
|

|
Preference-Conditioned Reinforcement Learning for Space-Time Efficient Online 3D Bin Packing
Nikita Sarawgi, Omey M. Manyar, Fan Wang, Thinh H. Nguyen, Daniel Seita, Satyandra K. Gupta
@inproceedings{sarawgi2026binpacking,
title={{Preference-Conditioned Reinforcement Learning for Space-Time Efficient Online 3D Bin Packing}},
author={Nikita Sarawgi and Omey M. Manyar and Fan Wang and Thinh H. Nguyen and Daniel Seita and Satyandra K. Gupta},
booktitle={International Conference on Robotics and Automation (ICRA)},
Year={2026}
}
IEEE International Conference on Robotics and Automation (ICRA), 2026.
|
|
Causally Robust Reward Learning From Reason-Augmented Preference Feedback
Minjune Hwang, Yigit Korkmaz, Daniel Seita†, Erdem Bıyık†
@inproceedings{hwang2026recouple,
title={{Causally Robust Reward Learning From Reason-Augmented Preference Feedback}},
author={Minjune Hwang and Yigit Korkmaz and Daniel Seita and Erdem Bıyık},
booktitle={International Conference on Learning Representations (ICLR)},
Year={2026}
}
International Conference on Learning Representations (ICLR), 2026.
|

|
D-REX: Differentiable Real-to-Sim-to-Real Engine for Learning Dexterous Grasping
Haozhe Lou*, Mingtong Zhang*, Haoran Geng, Hanyang Zhou, Sicheng He, Zhiyuan Gao, Siheng Zhao, Jiageng Mao, Pieter Abbeel, Jitendra Malik, Daniel Seita, Yue Wang
@inproceedings{lou2026DREX,
title={{D-REX: Differentiable Real-to-Sim-to-Real Engine for Learning Dexterous Grasping}},
author={Haozhe Lou and Mingtong Zhang and Haoran Geng and Hanyang Zhou and Sicheng He and Zhiyuan Gao and Siheng Zhao and Jiageng Mao and Pieter Abbeel and Jitendra Malik and Daniel Seita and Yue Wang},
booktitle={International Conference on Learning Representations (ICLR)},
Year={2026}
}
International Conference on Learning Representations (ICLR), 2026.
|

|
ManipBench: Benchmarking Vision-Language Models for Low-Level Robot Manipulation
Enyu Zhao*, Vedant Raval*, Hejia Zhang*, Jiageng Mao, Zeyu Shangguan, Stefanos Nikolaidis, Yue Wang, Daniel Seita
@inproceedings{zhao2025ManipBench,
title={{ManipBench: Benchmarking Vision-Language Models for Low-Level Robot Manipulation}},
author={Enyu Zhao and Vedant Raval and Hejia Zhang and Jiageng Mao and Zeyu Shangguan and Stefanos Nikolaidis and Yue Wang and Daniel Seita},
booktitle={Conference on Robot Learning (CoRL)},
Year={2025}
}
Conference on Robot Learning (CoRL), 2025.
|

|
D-CODA: Diffusion for Coordinated Dual-Arm Data Augmentation
I-Chun Arthur Liu, Jason Chen, Gaurav Sukhatme, Daniel Seita
@inproceedings{liu2025DCODA,
title={{D-CODA: Diffusion for Coordinated Dual-Arm Data Augmentation}},
author={I-Chun Arthur Liu and Jason Chen and Gaurav Sukhatme and Daniel Seita},
booktitle={Conference on Robot Learning (CoRL)},
Year={2025}
}
Conference on Robot Learning (CoRL), 2025.
|

|
Granular Loco-Manipulation: Repositioning Rocks Through Strategic Sand Avalanche
Haodi Hu, Yue Wu, Feifei Qian†, Daniel Seita†
@inproceedings{hu2025DiffusiveGRAIN,
title={{Granular Loco-Manipulation: Repositioning Rocks Through Strategic Sand Avalanche}},
author={Haodi Hu and Yue Wu and Feifei Qian and Daniel Seita},
booktitle={Conference on Robot Learning (CoRL)},
Year={2025}
}
Conference on Robot Learning (CoRL), 2025.
|

|
Robot Learning from Any Images
Siheng Zhao*, Jiageng Mao*, Wei Chow, Zeyu Shangguan, Tianheng Shi, Rong Xue, Yuxi Zheng, Yijia Weng, Yang You, Daniel Seita, Leonidas Guibas, Sergey Zakharov, Vitor Campagnolo Guizilini, Yue Wang
@inproceedings{zhao2025RoLA,
title={{Robot Learning from Any Images}},
author={Siheng Zhao and Jiageng Mao and Wei Chow and Zeyu Shangguan and Tianheng Shi and Rong Xue and Yuxi Zheng and Yijia Weng and Yang You and Daniel Seita and Leonidas Guibas and Sergey Zakharov and Vitor Campagnolo Guizilini and Yue Wang},
booktitle={Conference on Robot Learning (CoRL)},
Year={2025}
}
Conference on Robot Learning (CoRL), 2025.
|

|
Sequential Multi-Object Grasping with One Dexterous Hand
Sicheng He, Zeyu Shangguan, Kuanning Wang, Yongchong Gu, Yuqian Fu, Yanwei Fu, Daniel Seita
@inproceedings{he2025seqdex,
title={{Sequential Multi-Object Grasping with One Dexterous Hand}},
author={Sicheng He and Zeyu Shangguan and Kuanning Wang and Yongchong Gu and Yuqian Fu and Yanwei Fu and Daniel Seita},
booktitle={International Conference on Intelligent Robots and Systems (IROS)},
Year={2025}
}
IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2025.
|

|
The MOTIF Hand: A Robotic Hand for Multimodal Observations with Thermal, Inertial, and Force Sensors
Hanyang Zhou*, Haozhe Lou*, Wenhao Liu*, Enyu Zhao, Yue Wang, Daniel Seita
@inproceedings{Zhou2025MOTIF,
title={{The MOTIF Hand: A Robotic Hand for Multimodal Observations with Thermal, Inertial, and Force Sensors}},
author={Hanyang Zhou and Haozhe Lou and Wenhao Liu and Enyu Zhao and Yue Wang and Daniel Seita},
booktitle={International Symposium on Experimental Robotics (ISER)},
Year={2025}
}
International Symposium on Experimental Robotics (ISER), 2025
|

|
HRIBench: Benchmarking Vision-Language Models for Real-Time Human Perception in Human-Robot Interaction
Zhonghao Shi, Enyu Zhao, Nathaniel Dennler, Jingzhen Wang, Xinyang Xu, Kaleen Shrestha, Mengxue Fu, Daniel Seita, Maja Mataric
@inproceedings{Shi2025HRIBench,
title = {{HRIBench: Benchmarking Vision-Language Models for Real-Time Human Perception in Human-Robot Interaction}},
author={Zhonghao Shi and Enyu Zhao and Nathaniel Dennler and Jingzhen Wang and Xinyang Xu and Kaleen Shrestha and Mengxue Fu and Daniel Seita and Maja Mataric},
booktitle={International Symposium on Experimental Robotics (ISER)},
Year = {2025}
}
International Symposium on Experimental Robotics (ISER), 2025
|

|
PhysBench: Benchmarking and Enhancing Vision-Language Models for Physical World Understanding
Wei Chow*, Jiageng Mao*, Boyi Li, Daniel Seita, Vitor Campagnolo Guizilini, Yue Wang
@inproceedings{chow2025physbench,
title = {{PhysBench: Benchmarking and Enhancing Vision-Language Models for Physical World Understanding}},
author = {Wei Chow and Jiageng Mao and Boyi Li and Daniel Seita and Vitor Campagnolo Guizilini and Yue Wang},
booktitle = {International Conference on Learning Representations (ICLR)},
Year = {2025}
}
International Conference on Learning Representations (ICLR), 2025 - Oral Presentation (Top 1.8%)
|

|
Cross-domain Multi-modal Few-shot Object Detection via Rich Text
Zeyu Shangguan, Daniel Seita, Mohammad Rostami
@inproceedings{zeyu2025cdmmfsod,
title = {{Cross-domain Multi-modal Few-shot Object Detection via Rich Text}},
author = {Zeyu Shangguan and Daniel Seita and Mohammad Rostami},
booktitle = {IEEE/CVF Winter Conference on Applications of Computer Vision (WACV)},
Year = {2025}
}
IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 2025
|

|
Learning to Singulate Objects in Packed Environments using a Dexterous Hand
Hao Jiang, Yuhai Wang†, Hanyang Zhou†, Daniel Seita
@inproceedings{Hao2024SopeDex,
title = {{Learning to Singulate Objects in Packed Environments using a Dexterous Hand}},
author = {Hao Jiang and Yuhai Wang and Hanyang Zhou and Daniel Seita},
booktitle = {International Symposium of Robotics Research (ISRR)},
Year = {2024}
}
International Symposium of Robotics Research (ISRR), 2024
|

|
GPT-Fabric: Smoothing and Folding Fabric by Leveraging Pre-Trained Foundation Models
Vedant Raval*, Enyu Zhao*, Hejia Zhang, Stefanos Nikolaidis, Daniel Seita
@inproceedings{raval2024gptfabric,
title = {{GPT-Fabric: Smoothing and Folding Fabric by Leveraging Pre-Trained Foundation Models}},
author = {Vedant Raval and Enyu Zhao and Hejia Zhang and Stefanos Nikolaidis and Daniel Seita},
booktitle = {International Symposium of Robotics Research (ISRR)},
Year = {2024}
}
International Symposium of Robotics Research (ISRR), 2024
|

|
Learning Granular Media Avalanche Behavior for Indirectly Manipulating Obstacles on a Granular Slope
Haodi Hu, Feifei Qian†, Daniel Seita†
@inproceedings{hu2024grain,
title = {{Learning Granular Media Avalanche Behavior for Indirectly Manipulating Obstacles on a Granular Slope}},
author = {Haodi Hu and Feifei Qian and Daniel Seita},
booktitle = {Conference on Robot Learning (CoRL)},
Year = {2024}
}
Conference on Robot Learning (CoRL), 2024
|

|
VoxAct-B: Voxel-Based Acting and Stabilizing Policy for Bimanual Manipulation
I-Chun Arthur Liu, Sicheng He, Daniel Seita†, Gaurav Sukhatme†
@inproceedings{liu2024voxactb,
title = {{VoxAct-B: Voxel-Based Acting and Stabilizing Policy for Bimanual Manipulation}},
author = {I-Chun Arthur Liu and Sicheng He and Daniel Seita and Gaurav Sukhatme},
booktitle = {Conference on Robot Learning (CoRL)},
Year = {2024}
}
Conference on Robot Learning (CoRL), 2024
|

|
Bagging by Learning to Singulate Layers Using Interactive Perception
Lawrence Yunliang Chen, Baiyu Shi, Roy Lin, Daniel Seita, Ayah Ahmad, Richard Cheng, Thomas Kollar, David Held, Ken Goldberg
@inproceedings{slipbagging2023,
title={{Bagging by Learning to Singulate Layers Using Interactive Perception}},
author={Lawrence Yunliang Chen and Baiyu Shi and Roy Lin and Daniel Seita and Ayah Ahmad and Richard Cheng and Thomas Kollar and David Held and Ken Goldberg},
booktitle={International Conference on Intelligent Robots and Systems (IROS)},
year={2023}
}
IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2023
|

|
AutoBag: Learning to Open Plastic Bags and Insert Objects
Lawrence Yunliang Chen, Baiyu Shi, Daniel Seita, Richard Cheng, Thomas Kollar, David Held, Ken Goldberg
@inproceedings{autobag2023,
title={{AutoBag: Learning to Open Plastic Bags and Insert Objects}},
author={Lawrence Yunliang Chen and Baiyu Shi and Daniel Seita and Richard Cheng and Thomas Kollar and David Held and Ken Goldberg and Ken Goldberg and Ken Goldberg and Ken Goldberg and Ken Goldberg and Ken Goldberg},
booktitle={International Conference on Robotics and Automation (ICRA)},
year={2023}
}
IEEE International Conference on Robotics and Automation (ICRA), 2023
|

|
ToolFlowNet: Robotic Manipulation with Tools via Predicting Tool Flow from Point Clouds
Daniel Seita, Yufei Wang†, Sarthak J Shetty†, Edward Yao Li†, Zackory Erickson, David Held
Conference on Robot Learning (CoRL), 2022
|

|
Learning to Singulate Layers of Cloth Using Tactile Feedback
Sashank Tirumala*, Thomas Weng*, Daniel Seita*, Oliver Kroemer, Zeynep Temel, David Held
@inproceedings{tirumala2022reskin,
title={{Learning to Singulate Layers of Cloth using Tactile Feedback}},
author={Tirumala, Sashank and Weng, Thomas and Seita, Daniel and Kroemer, Oliver and Temel, Zeynep and Held, David},
booktitle={International Conference on Intelligent Robots and Systems (IROS)},
year={2022}
}
IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2022 - Best Paper at ROMADO-SI
|

|
Efficiently Learning Single-Arm Fling Motions to Smooth Garments
Lawrence Yunliang Chen*, Huang Huang*, Ellen Novoseller, Daniel Seita, Jeffrey Ichnowski, Michael Laskey, Richard Cheng, Thomas Kollar, Ken Goldberg
@inproceedings{flinging_2022,
title={{Efficiently Learning Single-Arm Fling Motions to Smooth Garments}},
author={Lawrence Yunliang Chen and Huang Huang and Ellen Novoseller and Daniel Seita and Jeffrey Ichnowski and Michael Laskey and Richard Cheng and Thomas Kollar and Ken Goldberg},
booktitle={International Symposium on Robotics Research (ISRR)},
Year={2022}
}
International Symposium on Robotics Research (ISRR), 2022
|

|
Automating Surgical Peg Transfer: Calibration with Deep Learning Can Exceed Speed, Accuracy, and Consistency of Humans
Minho Hwang, Jeffrey Ichnowski, Brijen Thananjeyan, Daniel Seita, Samuel Paradis, Danyal Fer, Thomas Low, Ken Goldberg
@inproceedings{minho_superhuman_2022,
title = {{Automating Surgical Peg Transfer: Calibration with Deep Learning Can Exceed Speed, Accuracy, and Consistency of Humans}},
author = {Minho Hwang and Jeffrey Ichnowski and Brijen Thananjeyan and Daniel Seita and Samuel Paradis and Danyal Fer and Thomas Low and Ken Goldberg},
booktitle = {IEEE Transactions on Automation Science and Engineering (TASE)},
Year = {2022}
}
Transactions on Automation Science and Engineering (T-ASE), 2022
|

|
Planar Robot Casting with Real2Sim2Real Self-Supervised Learning
Vincent Lim*, Huang Huang*, Yunliang Chen, Jonathan Wang, Jeffrey Ichnowski, Daniel Seita, Michael Laskey, Ken Goldberg
@inproceedings{lim2022planar,
title = {{Planar Robot Casting with Real2Sim2Real Self-Supervised Learning}},
author = {Vincent Lim and Huang Huang and Lawrence Yunliang Chen and Jonathan Wang and Jeffrey Ichnowski and Daniel Seita and Michael Laskey and Ken Goldberg},
booktitle = {IEEE International Conference on Robotics and Automation (ICRA)},
year = {2022}
}
IEEE International Conference on Robotics and Automation (ICRA), 2022
|

|
VisuoSpatial Foresight for Physical Sequential Fabric Manipulation
Ryan Hoque*, Daniel Seita*, Ashwin Balakrishna, Aditya Ganapathi, Ajay Tanwani, Nawid Jamali, Katsu Yamane, Soshi Iba, Ken Goldberg
@article{fabric_vsf_2021,
title = {{VisuoSpatial Foresight for Physical Sequential Fabric Manipulation}},
author = {Ryan Hoque and Daniel Seita and Ashwin Balakrishna and Aditya Ganapathi and Ajay Tanwani and Nawid Jamali and Katsu Yamane and Soshi Iba and Ken Goldberg},
journal = {arXiv preprint arXiv:2102.09754},
Year = {2021}
}
Autonomous Robots (AURO), 2021
|

|
LazyDAgger: Reducing Context Switching in Interactive Imitation Learning
Ryan Hoque, Ashwin Balakrishna, Carl Putterman, Michael Luo, Daniel Brown, Daniel Seita, Brijen Thananjeyan, Ellen Novoseller, Ken Goldberg
@inproceedings{lazydagger_2021,
title = {{LazyDAgger: Reducing Context Switching in Interactive Imitation Learning}},
author = {Ryan Hoque and Ashwin Balakrishna and Carl Putterman and Michael Luo and Daniel S. Brown and Daniel Seita and Brijen Thananjeyan and Ellen Novoseller and Ken Goldberg},
booktitle = {IEEE International Conference on Automation Science and Engineering (CASE)},
Year = {2021}
}
IEEE International Conference on Automation Science and Engineering (CASE), 2021
|
|
Learning to Rearrange Deformable Cables, Fabrics, and Bags with Goal-Conditioned Transporter Networks
Daniel Seita, Pete Florence, Jonathan Tompson, Erwin Coumans, Vikas Sindhwani, Ken Goldberg, Andy Zeng
@inproceedings{seita_bags_2021,
title = {{Learning to Rearrange Deformable Cables, Fabrics, and Bags with Goal-Conditioned Transporter Networks}},
author = {Daniel Seita and Pete Florence and Jonathan Tompson and Erwin Coumans and Vikas Sindhwani and Ken Goldberg and Andy Zeng},
booktitle = {IEEE International Conference on Robotics and Automation (ICRA)},
Year = {2021}
}
IEEE International Conference on Robotics and Automation (ICRA), 2021
|

|
Robots of the Lost Arc: Self-Supervised Learning to Dynamically Manipulate Fixed-Endpoint Cables
Harry Zhang, Jeffrey Ichnowski, Daniel Seita, Jonathan Wang, Huang Huang, Ken Goldberg
@inproceedings{harry_rope_2021,
title = {{Robots of the Lost Arc: Self-Supervised Learning to Dynamically Manipulate Fixed-Endpoint Cables}},
author = {Harry Zhang and Jeff Ichnowski and Daniel Seita and Jonathan Wang and Huang Huang and Ken Goldberg},
booktitle = {IEEE International Conference on Robotics and Automation (ICRA)},
Year = {2021}
}
IEEE International Conference on Robotics and Automation (ICRA), 2021
|

|
Learning Dense Visual Correspondences in Simulation to Smooth and Fold Real Fabrics
Aditya Ganapathi, Priya Sundaresan, Brijen Thananjeyan, Ashwin Balakrishna, Daniel Seita, Jennifer Grannen, Minho Hwang, Ryan Hoque, Joseph Gonzalez, Nawid Jamali, Katsu Yamane, Soshi Iba, Ken Goldberg
@inproceedings{descriptors_fabrics_2021,
title = {{Learning Dense Visual Correspondences in Simulation to Smooth and Fold Real Fabrics}},
author = {Aditya Ganapathi and Priya Sundaresan and Brijen Thananjeyan and Ashwin Balakrishna and Daniel Seita and Jennifer Grannen and Minho Hwang and Ryan Hoque and Joseph Gonzalez and Nawid Jamali and Katsu Yamane and Soshi Iba and Ken Goldberg},
booktitle = {IEEE International Conference on Robotics and Automation (ICRA)},
Year = {2021}
}
IEEE International Conference on Robotics and Automation (ICRA), 2021
|

|
Intermittent Visual Servoing: Efficiently Learning Policies Robust to Tool Changes for High-precision Surgical Manipulation
Samuel Paradis, Minho Hwang, Brijen Thananjeyan, Jeffrey Ichnowski, Daniel Seita, Danyal Fer, Thomas Low, Joseph E. Gonzalez, Ken Goldberg
@inproceedings{sam_ivs_2021,
title = {{Intermittent Visual Servoing: Efficiently Learning Policies Robust to Instrument Changes for High-precision Surgical Manipulation}},
author = {Samuel Paradis and Minho Hwang and Brijen Thananjeyan and Jeffrey Ichnowski and Daniel Seita and Danyal Fer and Thomas Low and Joseph E. Gonzalez and Ken Goldberg},
booktitle = {IEEE International Conference on Robotics and Automation (ICRA)},
Year = {2021}
}
IEEE International Conference on Robotics and Automation (ICRA), 2021
|

|
Deep Imitation Learning of Sequential Fabric Smoothing From an Algorithmic Supervisor
Daniel Seita, Aditya Ganapathi, Ryan Hoque, Minho Hwang, Edward Cen, Ajay Kumar Tanwani, Ashwin Balakrishna, Brijen Thananjeyan, Jeffrey Ichnowski, Nawid Jamali, Kastu Yamane, Soshi Iba, John Canny, Ken Goldberg
@inproceedings{seita_fabrics_2020,
title = {{Deep Imitation Learning of Sequential Fabric Smoothing From an Algorithmic Supervisor}},
author = {Daniel Seita and Aditya Ganapathi and Ryan Hoque and Minho Hwang and Edward Cen and Ajay Kumar Tanwani and Ashwin Balakrishna and Brijen Thananjeyan and Jeffrey Ichnowski and Nawid Jamali and Katsu Yamane and Soshi Iba and John Canny and Ken Goldberg},
booktitle = {IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)},
Year = {2020}
}
IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2020
|

|
Efficiently Calibrating Cable-Driven Surgical Robots with RGBD Fiducial Sensing and Recurrent Neural Networks
Minho Hwang, Brijen Thananjeyan, Samuel Paradis, Daniel Seita, Jeffrey Ichnowski, Danyal Fer, Thomas Low, Ken Goldberg
@inproceedings{minho_calibration_2020,
title = {{Efficiently Calibrating Cable-Driven Surgical Robots with RGBD Fiducial Sensing and Recurrent Neural Networks}},
author = {Minho Hwang and Brijen Thananjeyan and Samuel Paradis and Daniel Seita and Jeffrey Ichnowski and Danyal Fer and Thomas Low and Ken Goldberg},
booktitle = {IEEE Robotics and Automation Letters (RA-L)},
Year = {2020}
}
IEEE Robotics and Automation Letters (RA-L), 2020
|

|
VisuoSpatial Foresight for Multi-Step, Multi-Task Fabric Manipulation
Ryan Hoque*, Daniel Seita*, Ashwin Balakrishna, Aditya Ganapathi, Ajay Tanwani, Nawid Jamali, Katsu Yamane, Soshi Iba, Ken Goldberg
Robotics: Science and Systems (RSS), 2020
|

|
Applying Depth-Sensing to Automated Surgical Manipulation with a da Vinci Robot
Minho Hwang*, Daniel Seita*, Brijen Thananjeyan, Jeff Ichnowski, Samuel Paradis, Danyal Fer, Thomas Low, Ken Goldberg
@inproceedings{minho_pegs_2020,
title = {{Applying Depth-Sensing to Automated Surgical Manipulation with a da Vinci Robot}},
author = {Minho Hwang and Daniel Seita and Brijen Thananjeyan and Jeffrey Ichnowski and Samuel Paradis and Danyal Fer and Thomas Low and Ken Goldberg},
booktitle = {International Symposium on Medical Robotics (ISMR)},
Year = {2020}
}
International Symposium on Medical Robotics (ISMR), 2020
|

|
Deep Transfer Learning of Pick Points on Fabric for Robot Bed-Making
Daniel Seita*, Nawid Jamali*, Michael Laskey*, Ron Berenstein, Ajay Tanwani, Prakash Baskaran, Soshi Iba, John Canny, Ken Goldberg
@inproceedings{seita_bedmake_2019,
title = {{Deep Transfer Learning of Pick Points on Fabric for Robot Bed-Making}},
author = {Daniel Seita and Nawid Jamali and Michael Laskey and Ron Berenstein and Ajay Kumar Tanwani and Prakash Baskaran and Soshi Iba and John Canny and Ken Goldberg},
booktitle = {International Symposium on Robotics Research (ISRR)},
Year = {2019}
}
International Symposium on Robotics Research (ISRR), 2019
|
|
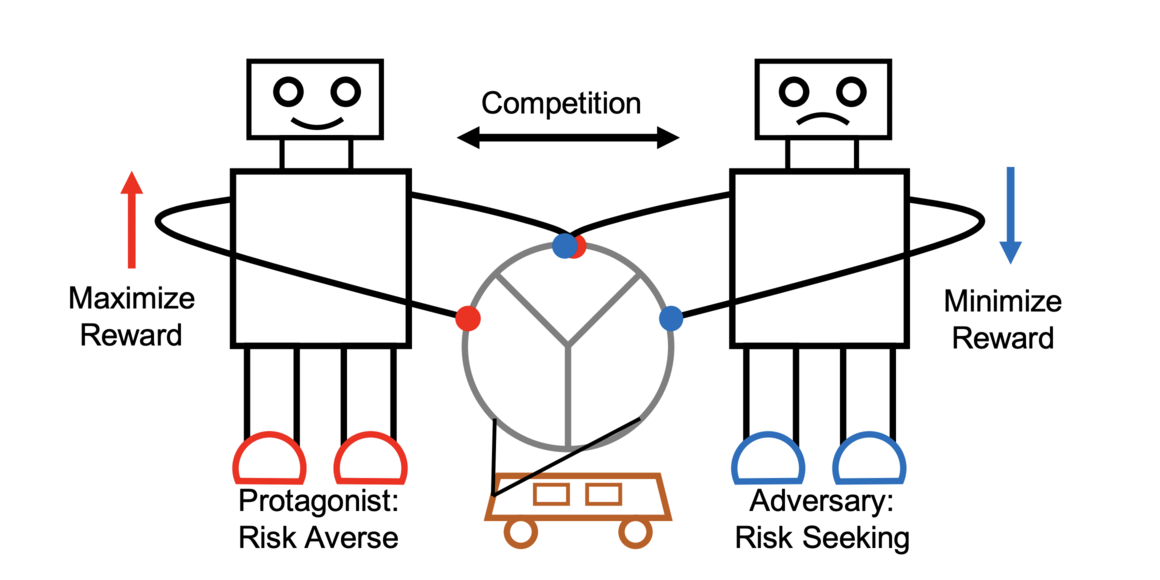
Risk Averse Robust Adversarial Reinforcement Learning
Xinlei Pan, Daniel Seita, Yang Gao, John Canny
@inproceedings{xinlei_icra_2019,
title = {{Risk Averse Robust Adversarial Reinforcement Learning}},
author = {Xinlei Pan and Daniel Seita and Yang Gao and John Canny},
booktitle = {IEEE International Conference on Robotics and Automation (ICRA)},
Year = {2019}
}
IEEE International Conference on Robotics and Automation (ICRA), 2019
|
|
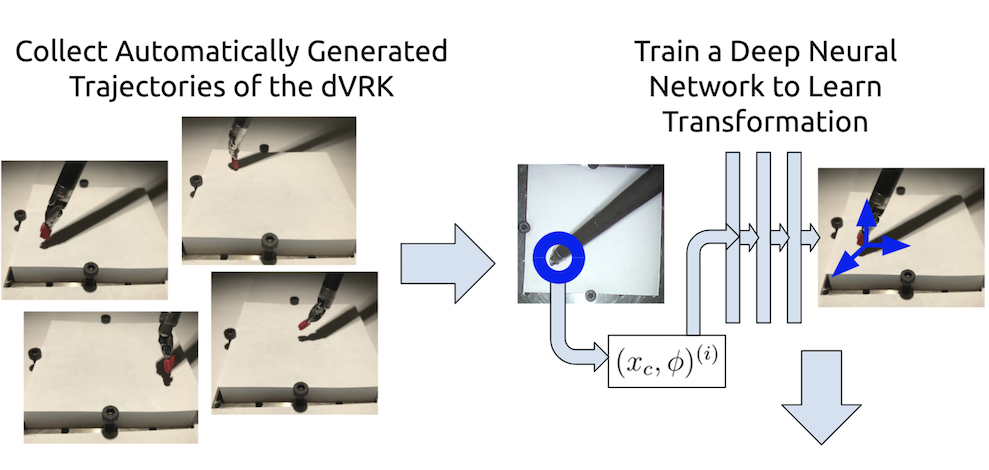
Fast and Reliable Autonomous Surgical Debridement with Cable-Driven Robots Using a Two-Phase Calibration Procedure
Daniel Seita, Sanjay Krishnan, Roy Fox, Stephen McKinley, John Canny, Ken Goldberg
@inproceedings{seita_icra_2018,
title = {{Fast and Reliable Autonomous Surgical Debridement with Cable-Driven Robots Using a Two-Phase Calibration Procedure}},
author = {Daniel Seita and Sanjay Krishnan and Roy Fox and Stephen McKinley and John Canny and Kenneth Goldberg},
booktitle = {IEEE International Conference on Robotics and Automation (ICRA)},
Year = {2018}
}
IEEE International Conference on Robotics and Automation (ICRA), 2018
|
|
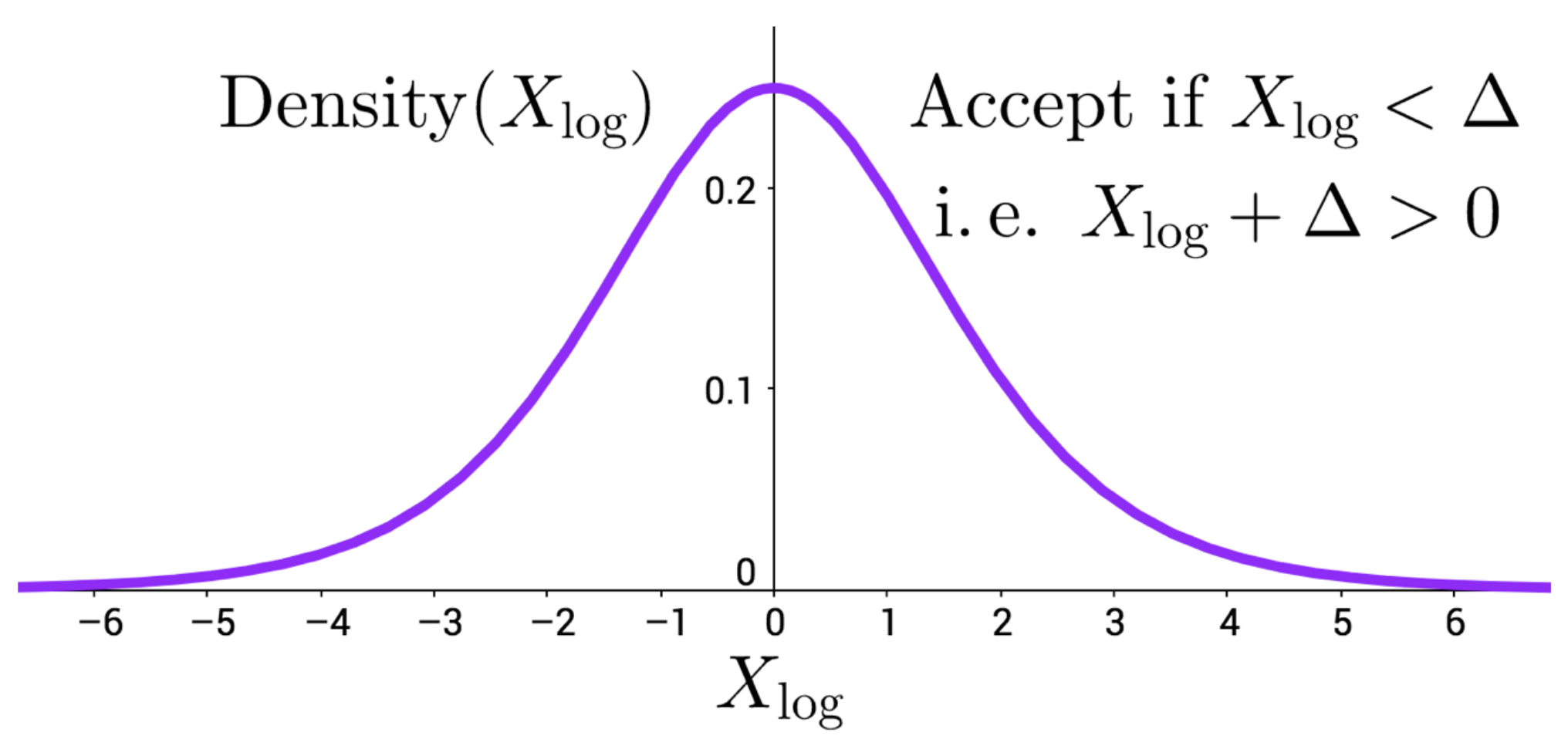
An Efficient Minibatch Acceptance Test for Metropolis-Hastings
Daniel Seita, Xinlei Pan, Haoyu Chen, John Canny
@inproceedings{seita_uai_2017,
title = {{An Efficient Minibatch Acceptance Test for Metropolis-Hastings}},
author = {Seita, Daniel and Pan, Xinlei and Chen, Haoyu and Canny, John},
booktitle = {Conference on Uncertainty in Artificial Intelligence (UAI)},
year = {2017}
}
Uncertainty in Artificial Intelligence (UAI), 2017 - Honorable Mention for Best Student Paper
|

|
Large-Scale Supervised Learning of the Grasp Robustness of Surface Patch Pairs
Daniel Seita, Florian T. Pokorny, Jeffrey Mahler, Danica Kragic, Michael Franklin, John Canny, Ken Goldberg
@inproceedings{seita_simpar_2016,
title = {{Large-Scale Supervised Learning of the Grasp Robustness of Surface Patch Pairs}},
author = {Daniel Seita and Florian T. Pokorny and Jeffrey Mahler and Danica Kragic and Michael Franklin and John Canny and Ken Goldberg},
booktitle = {IEEE International Conference on Simulation, Modeling, and Programming for Autonomous Robots (SIMPAR)},
Year = {2016}
}
International Conference on Simulation, Modeling, and Programming for Autonomous Robots (SIMPAR), 2016
|
