|
LAM: Language Articulated Object Modelers
Yipeng Gao, Yunhao Ge, Peilin Cai, Daniel Seita, Laurent Itti
@inproceedings{gao2026LAM,
title={{LAM: Language Articulated Object Modelers}},
author={Yipeng Gao and Yunhao Ge and Peilin Cai and Daniel Seita and Laurent Itti},
booktitle={Computer Vision and Pattern Recognition (CVPR)},
Year={2026}
}
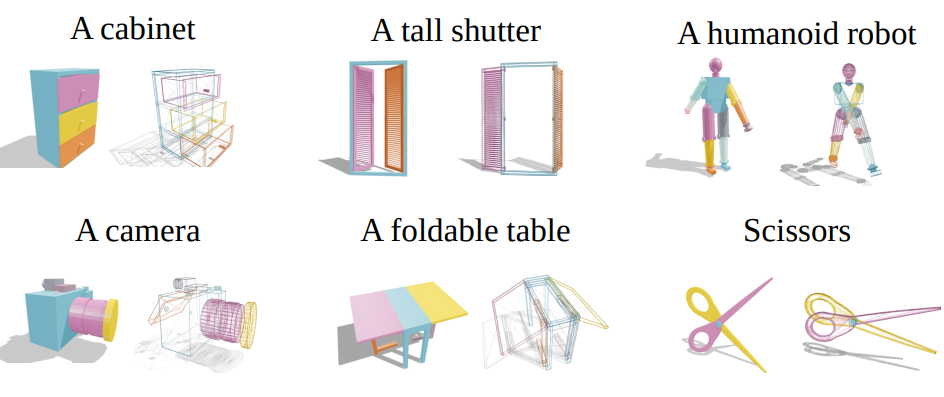
We introduce LAM, a system that explores the collaboration of large-language models and vision-language models to generate articulated objects from text prompts. Our approach differs from previous methods that either rely on input visual structure (e.g., an image) or assemble articulated models from pre-built assets. In contrast, we formulate articulated object generation as a unified code generation task, where geometry and articulations can be co-designed from scratch. Given an input text, LAM coordinates a team of specialized modules to generate code to represent the desired articulated object procedurally. The LAM first reasons about the hierarchical structure of parts (links) with Link Designer, then writes code, compiles it, and debugs it with Geometry & Articulation Coders and self-corrects with Geometry & Articulation Checkers. The code serves as a structured and interpretable bridge between individual links, ensuring correct relationships among them. Representing everything with code allows the system to determine appropriate joint types and calculate their exact placements more reliably. Experiments demonstrate the power of leveraging code as a generative medium within an agentic system, showcasing its effectiveness in automatically constructing complex articulated objects.
Computer Vision and Pattern Recognition (CVPR), 2026.
|

|
ROPA: Synthetic Robot Pose Generation for RGB-D Bimanual Data Augmentation
Jason Chen, I-Chun Arthur Liu, Gaurav Sukhatme, Daniel Seita
@inproceedings{chen2026ropa,
title={{ROPA: Synthetic Robot Pose Generation for RGB-D Bimanual Data Augmentation}},
author={Jason Chen and I-Chun Arthur Liu and Gaurav Sukhatme and Daniel Seita},
booktitle={International Conference on Robotics and Automation (ICRA)},
Year={2026}
}
Training robust bimanual manipulation policies via imitation learning requires demonstration data with broad coverage over robot poses, contacts, and scene contexts. However, collecting diverse and precise real-world demonstrations is costly and time-consuming, which hinders scalability. Prior works have addressed this with data augmentation, typically for either eye-in-hand (wrist camera) setups with RGB inputs or for generating novel images without paired actions, leaving augmentation for eye-to-hand (third-person) RGB-D training with new action labels less explored. In this paper, we propose Synthetic Robot Pose Generation for RGB-D Bimanual Data Augmentation (ROPA), an offline imitation learning data augmentation method that fine-tunes Stable Diffusion to synthesize third-person RGB and RGB-D observations of novel robot poses. Our approach simultaneously generates corresponding joint-space action labels while employing constrained optimization to enforce physical consistency through appropriate gripper-to-object contact constraints in bimanual scenarios. We evaluate our method on 5 simulated and 3 real-world tasks. Our results across 2625 simulation trials and 300 real-world trials demonstrate that ROPA outperforms baselines and ablations, showing its potential for scalable RGB and RGB-D data augmentation in eye-to-hand bimanual manipulation.
International Conference on Robotics and Automation (ICRA), 2026.
|

|
Learning Geometry-Aware Nonprehensile Pushing and Pulling with Dexterous Hands
Yunshuang Li, Yiyang Ling, Gaurav Sukhatme, Daniel Seita
@inproceedings{li2026nonprehensile,
title={{Learning Geometry-Aware Nonprehensile Pushing and Pulling with Dexterous Hands}},
author={Yunshuang Li and Yiyang Ling and Gaurav Sukhatme and Daniel Seita},
booktitle={International Conference on Robotics and Automation (ICRA)},
Year={2026}
}
Nonprehensile manipulation, such as pushing and pulling, enables robots to move, align, or reposition objects that may be difficult to grasp due to their geometry, size, or relationship to the robot or the environment. Much of the existing work in nonprehensile manipulation relies on parallel-jaw grippers or tools such as rods and spatulas. In contrast, multi-fingered dexterous hands offer richer contact modes and versatility for handling diverse objects to provide stable support over the objects, which compensates for the difficulty of modeling the dynamics of nonprehensile manipulation. Therefore, we propose Geometry-aware Dexterous Pushing and Pulling (GD2P) for nonprehensile manipulation with dexterous robotic hands. We study pushing and pulling by framing the problem as synthesizing and learning pre-contact dexterous hand poses that lead to effective manipulation. We generate diverse hand poses via contact-guided sampling, filter them using physics simulation, and train a diffusion model conditioned on object geometry to predict viable poses. At test time, we sample hand poses and use standard motion planners to select and execute pushing and pulling actions. We perform 840 real-world experiments with an Allegro Hand, comparing our method to baselines. The results indicate that GD2P offers a scalable route for training dexterous nonprehensile manipulation policies. We further demonstrate GD2P on a LEAP Hand, highlighting its applicability to different hand morphologies. Our pre-trained models and dataset, including 1.3 million hand poses across 2.3k objects, will be open-source to facilitate further research.
International Conference on Robotics and Automation (ICRA), 2026.
|

|
IMPACT: Intelligent Motion Planning with Acceptable Contact Trajectories via Vision-Language Models
Yiyang Ling*, Karan Owalekar*, Oluwatobiloba Adesanya, Erdem Bıyık, Daniel Seita
@inproceedings{ling2026impact,
title={{IMPACT: Intelligent Motion Planning with Acceptable Contact Trajectories via Vision-Language Models}},
author={Yiyang Ling and Karan Owalekar and Oluwatobiloba Adesanya and Erdem Bıyık and Daniel Seita},
booktitle={International Conference on Robotics and Automation (ICRA)},
Year={2026}
}
Motion planning involves determining a sequence of robot configurations to reach a desired pose, subject to movement and safety constraints. Traditional motion planning finds collision-free paths, but this is overly restrictive in clutter, where it may not be possible for a robot to accomplish a task without contact. In addition, contacts range from relatively benign (e.g. brushing a soft pillow) to more dangerous (e.g. toppling a glass vase), making it difficult to characterize which may be acceptable. In this paper, we propose IMPACT, a novel motion planning framework that uses Vision-Language Models (VLMs) to infer environment semantics, identifying which parts of the environment can best tolerate contact based on object properties and locations. Our approach generates an anisotropic cost map that encodes directional push safety. We pair this map with a contact-aware A* planner to find stable contact-rich paths. We perform experiments using 20 simulation and 10 real-world scenes and assess using task success rate, object displacements, and feedback from human evaluators. Our results over 3200 simulation and 200 real-world trials suggest that IMPACT enables efficient contact-rich motion planning in cluttered settings while outperforming alternative methods and ablations.
International Conference on Robotics and Automation (ICRA), 2026.
|
|
V-MORALS: Visual Morse Graph-Aided Discovery of Regions of Attraction in a Learned Space
Faiz Aladin, Ashwin Balasubramanian, Lars Lindemann, Daniel Seita
@inproceedings{aladin2026vmorals,
title={{V-MORALS: Visual Morse Graph-Aided Discovery of Regions of Attraction in a Learned Space}},
author={Faiz Aladin and Ashwin Balasubramanian and Lars Lindemann and Daniel Seita},
booktitle={International Conference on Robotics and Automation (ICRA)},
Year={2026}
}
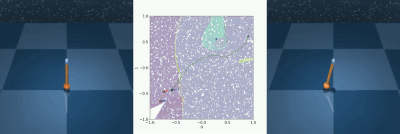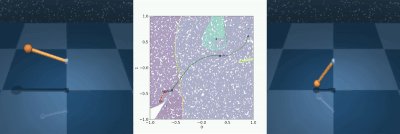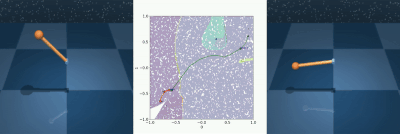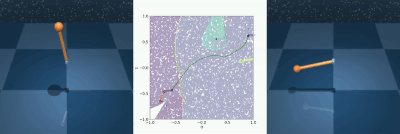
Reachability analysis has become increasingly important in robotics to distinguish safe from unsafe states. Unfortunately, existing reachability and safety analysis methods often fall short, as they typically require known system dynamics or large datasets to estimate accurate system models, are computationally expensive, and assume full state information. A recent method, called MORALS, aims to address these shortcomings by using topological tools to estimate Regions of Attraction (ROA) in a low-dimensional latent space. However, MORALS still relies on full state knowledge and has not been studied when only sensor measurements are available. This paper presents Visual Morse Graph-Aided Estimation of Regions of Attraction in a Learned Space (V-MORALS). V-MORALS takes in a dataset of image-based trajectories of a system under a given controller, and learns a latent space for reachability analysis. Using this learned latent space, our method is able to generate well-defined Morse Graphs, from which we can compute ROAs for various systems and controllers. V-MORALS provides capabilities similar to the original MORALS architecture without relying on state knowledge, and using only high-level sensor data.
International Conference on Robotics and Automation (ICRA), 2026.
|

|
SCOOP'D: State-based Sim2Real Generative Policy for Generalizable Mixed-Liquid-Solid Scooping
Kuanning Wang, Yongchong Gu, Yuqian Fu, Zeyu Shangguan, Sicheng He, Xiangyang Xue, Yanwei Fu, Daniel Seita
@inproceedings{wang2026scooping,
title={{SCOOP'D: State-based Sim2Real Generative Policy for Generalizable Mixed-Liquid-Solid Scooping}},
author={Kuanning Wang and Yongchong Gu and Yuqian Fu and Zeyu Shangguan and Sicheng He and Xiangyang Xue and Yanwei Fu and Daniel Seita},
booktitle={International Conference on Robotics and Automation (ICRA)},
Year={2026}
}
Scooping items with tools such as spoons and ladles is common in daily life, ranging from assistive feeding to retrieving items from environmental disaster sites. However, developing a general and autonomous robotic scooping policy is challenging since it requires reasoning about complex tool-object interactions. Furthermore, scooping often involves manipulating deformable objects, such as granular media or liquids, which is challenging due to their infinite-dimensional configuration spaces and complex dynamics. We propose a method, SCOOP'D, which uses simulation from OmniGibson (built on NVIDIA Omniverse) to collect scooping demonstrations using algorithmic procedures that rely on privileged state information. Then, we use generative policies via diffusion to imitate demonstrations from observational input. We directly apply the learned policy in diverse real-world scenarios, testing its performance on various item quantities, item characteristics, and container types. In zero-shot deployment, our method demonstrates promising results across 465 trials in diverse scenarios, including objects of different difficulty levels that we categorize as "Level 1" and "Level 2." SCOOP'D outperforms all baselines and ablations, suggesting that this is a promising approach to acquiring robotic scooping skills.
International Conference on Robotics and Automation (ICRA), 2026.
|
|
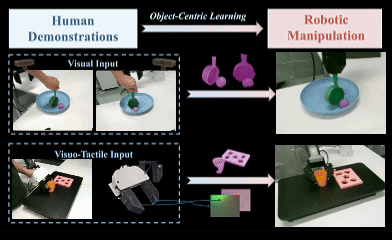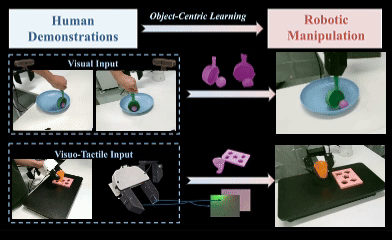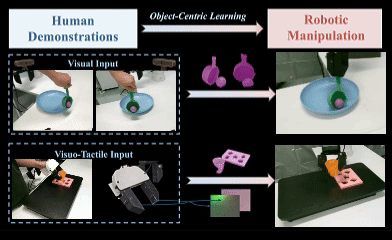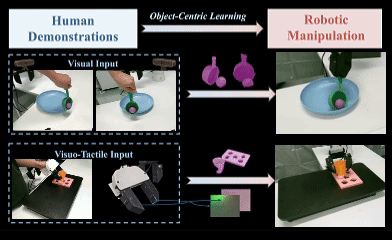
OCRA: Object-Centric Learning with 3D and Tactile Priors for Human-to-Robot Action Transfer
Kuanning Wang*, Ke Fan*, Yuqian Fu, Siyu Lin, Hu Luo, Daniel Seita, Yanwei Fu, Yu-Gang Jiang, Xiangyang Xue
@inproceedings{wang2026orca,
title={{OCRA: Object-Centric Learning with 3D and Tactile Priors for Human-to-Robot Action Transfer}},
author={Kuanning Wang and Ke Fan and Yuqian Fu and Siyu Lin and Hu Luo and Daniel Seita and Yanwei Fu and Yu{-}Gang Jiang and Xiangyang Xue},
booktitle={International Conference on Robotics and Automation (ICRA)},
Year={2026}
}
We present OCRA, an Object-Centric framework for video-based human-to-Robot Action transfer that learns directly from human demonstration videos to enable robust manipulation. Object-centric learning emphasizes task-relevant objects and their interactions while filtering out irrelevant background, providing a natural and scalable way to teach robots. OCRA leverages multi-view RGB videos, the state-of-the-art 3D foundation model VGGT, and advanced detection and segmentation models to reconstruct object-centric 3D point clouds, capturing rich interactions between objects. To handle properties not easily perceived by vision alone, we incorporate tactile priors via a large-scale dataset of over one million tactile images. These 3D and tactile priors are fused through a multimodal module (ResFiLM) and fed into a Diffusion Policy to generate robust manipulation actions. Extensive experiments on both vision-only and visuo-tactile tasks show that OCRA significantly outperforms existing baselines and ablations, demonstrating its effectiveness for learning from human demonstration videos.
International Conference on Robotics and Automation (ICRA), 2026.
|

|
Preference-Conditioned Reinforcement Learning for Space-Time Efficient Online 3D Bin Packing
Nikita Sarawgi, Omey M. Manyar, Fan Wang, Thinh H. Nguyen, Daniel Seita, Satyandra K. Gupta
@inproceedings{sarawgi2026binpacking,
title={{Preference-Conditioned Reinforcement Learning for Space-Time Efficient Online 3D Bin Packing}},
author={Nikita Sarawgi and Omey M. Manyar and Fan Wang and Thinh H. Nguyen and Daniel Seita and Satyandra K. Gupta},
booktitle={International Conference on Robotics and Automation (ICRA)},
Year={2026}
}
Robotic bin packing is widely deployed in warehouse automation, with current systems achieving robust performance through heuristic and learning-based strategies. These systems must balance compact placement with rapid execution, where selecting alternative items or reorienting them can improve space utilization but introduce additional time. We propose a selection-based formulation that explicitly reasons over this trade-off - at each step, the robot evaluates multiple candidate actions, weighing expected packing benefit against estimated operational time. This enables time-aware strategies that selectively accept increased operational time when it yields meaningful spatial improvements. Our method, STEP (Space-Time Efficient Packing), uses a preference-conditioned, Transformer-based reinforcement learning policy, and allows generalization across candidate set sizes and integration with standard placement modules. It achieves a 44% reduction in operational time without compromising packing density.
International Conference on Robotics and Automation (ICRA), 2026.
|
|
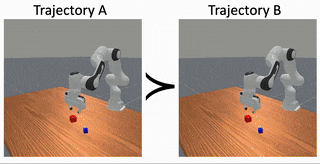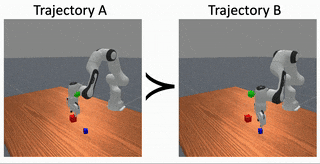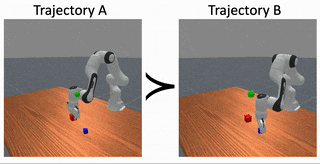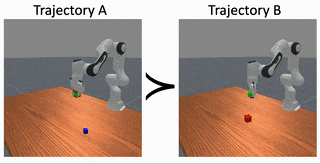
Causally Robust Reward Learning From Reason-Augmented Preference Feedback
Minjune Hwang, Yigit Korkmaz, Daniel Seita†, Erdem Bıyık†
@inproceedings{hwang2026recouple,
title={{Causally Robust Reward Learning From Reason-Augmented Preference Feedback}},
author={Minjune Hwang and Yigit Korkmaz and Daniel Seita and Erdem Bıyık},
booktitle={International Conference on Learning Representations (ICLR)},
Year={2026}
}
Preference‑based reward learning is widely used for shaping agent behavior to match a user's preference, yet its sparse binary feedback makes it especially vulnerable to causal confusion. The learned reward often latches onto spurious features that merely co‑occur with preferred trajectories during training, collapsing when those correlations disappear or reverse at test time. We introduce ReCouPLe, a lightweight framework that uses natural language rationales to provide the missing causal signal. Each rationale is treated as a guiding projection axis in embedding space, training the model to score trajectories based on features aligned with that axis while de-emphasizing context that is unrelated to the stated reason. Because identical rationales can arise across multiple tasks (e.g., "it avoids collisions with a fragile object"), ReCouPLe naturally reuses the same causal direction whenever tasks share semantics, and transfers preference knowledge to novel tasks without extra data or language‑model fine-tuning. Our learned reward model can ground preferences on the articulated reason, aligning better with user intent and generalizing beyond spurious features.
International Conference on Learning Representations (ICLR), 2026.
|

|
D-REX: Differentiable Real-to-Sim-to-Real Engine for Learning Dexterous Grasping
Haozhe Lou*, Mingtong Zhang*, Haoran Geng, Hanyang Zhou, Sicheng He, Zhiyuan Gao, Siheng Zhao, Jiageng Mao, Pieter Abbeel, Jitendra Malik, Daniel Seita, Yue Wang
@inproceedings{lou2026DREX,
title={{D-REX: Differentiable Real-to-Sim-to-Real Engine for Learning Dexterous Grasping}},
author={Haozhe Lou and Mingtong Zhang and Haoran Geng and Hanyang Zhou and Sicheng He and Zhiyuan Gao and Siheng Zhao and Jiageng Mao and Pieter Abbeel and Jitendra Malik and Daniel Seita and Yue Wang},
booktitle={International Conference on Learning Representations (ICLR)},
Year={2026}
}
Simulation provides a cost-effective and flexible platform for data generation and policy learning to develop robotic systems. However, bridging the gap between simulation and real-world dynamics remains a significant challenge, especially in physical parameter identification. In this work, we introduce a real-to-sim-to-real engine that leverages the Gaussian Splat representations to build a differentiable engine, enabling object mass identification from real-world visual observations and robot control signals, while enabling grasping policy learning simultaneously. Through optimizing the mass of the manipulated object, our method automatically builds high-fidelity and physically plausible digital twins. Additionally, we propose a novel approach to train force-aware grasping policies from limited data by transferring feasible human demonstrations into simulated robot demonstrations. Through comprehensive experiments, we demonstrate that our engine achieves accurate and robust performance in mass identification across various object geometries and mass values. Those optimized mass values facilitate force-aware policy learning, achieving superior and high performance in object grasping, effectively reducing the sim-to-real gap.
International Conference on Learning Representations (ICLR), 2026.
|

|
ManipBench: Benchmarking Vision-Language Models for Low-Level Robot Manipulation
Enyu Zhao*, Vedant Raval*, Hejia Zhang*, Jiageng Mao, Zeyu Shangguan, Stefanos Nikolaidis, Yue Wang, Daniel Seita
@inproceedings{zhao2025ManipBench,
title={{ManipBench: Benchmarking Vision-Language Models for Low-Level Robot Manipulation}},
author={Enyu Zhao and Vedant Raval and Hejia Zhang and Jiageng Mao and Zeyu Shangguan and Stefanos Nikolaidis and Yue Wang and Daniel Seita},
booktitle={Conference on Robot Learning (CoRL)},
Year={2025}
}
Vision-Language Models (VLMs) have revolutionized artificial intelligence and robotics due to their commonsense reasoning capabilities. In robotic manipulation, VLMs are used primarily as high-level planners, but recent work has also studied their lower-level reasoning ability, which refers to making decisions about precise robot movements. However, the community currently lacks a clear and common benchmark that can evaluate how well VLMs can aid low-level reasoning in robotics. Consequently, we propose a novel benchmark, ManipBench, to evaluate the low-level robot manipulation reasoning capabilities of VLMs across various dimensions, including how well they understand object-object interactions and deformable object manipulation. We extensively test 33 representative VLMs across 10 model families on our benchmark, including variants to test different model sizes. Our evaluation shows that the performance of VLMs significantly varies across tasks, and there is a strong correlation between this performance and trends in our real-world manipulation tasks. It also shows that there remains a significant gap between these models and human-level understanding.
Conference on Robot Learning (CoRL), 2025.
|

|
D-CODA: Diffusion for Coordinated Dual-Arm Data Augmentation
I-Chun Arthur Liu, Jason Chen, Gaurav Sukhatme, Daniel Seita
@inproceedings{liu2025DCODA,
title={{D-CODA: Diffusion for Coordinated Dual-Arm Data Augmentation}},
author={I-Chun Arthur Liu and Jason Chen and Gaurav Sukhatme and Daniel Seita},
booktitle={Conference on Robot Learning (CoRL)},
Year={2025}
}
Learning bimanual manipulation is challenging due to its high dimensionality and tight coordination required between two arms. Eye-in-hand imitation learning, which uses wrist-mounted cameras, simplifies perception by focusing on task-relevant views. However, collecting diverse demonstrations remains costly, motivating the need for scalable data augmentation. While prior work has explored visual augmentation in single-arm settings, extending these approaches to bimanual manipulation requires generating viewpoint-consistent observations across both arms and producing corresponding action labels that are both valid and feasible. In this work, we propose Diffusion for COordinated Dual-arm Data Augmentation (D-CODA), a method for offline data augmentation tailored to eye-in-hand bimanual imitation learning that trains a diffusion model to synthesize novel, viewpoint-consistent wrist-camera images for both arms while simultaneously generating joint-space action labels. It employs constrained optimization to ensure that augmented states involving gripper-to-object contacts adhere to constraints suitable for bimanual coordination. We evaluate D-CODA on 5 simulated and 3 real-world tasks. Our results across 2250 simulation trials and 300 real-world trials demonstrate that it outperforms baselines and ablations, showing its potential for scalable data augmentation in eye-in-hand bimanual manipulation.
Conference on Robot Learning (CoRL), 2025.
|

|
Granular Loco-Manipulation: Repositioning Rocks Through Strategic Sand Avalanche
Haodi Hu, Yue Wu, Feifei Qian†, Daniel Seita†
@inproceedings{hu2025DiffusiveGRAIN,
title={{Granular Loco-Manipulation: Repositioning Rocks Through Strategic Sand Avalanche}},
author={Haodi Hu and Yue Wu and Feifei Qian and Daniel Seita},
booktitle={Conference on Robot Learning (CoRL)},
Year={2025}
}
Legged robots have the potential to leverage obstacles to climb steep sand slopes. However, efficiently repositioning these obstacles to desired locations is challenging. Here we present DiffusiveGRAIN, a learning-based method that enables a multi-legged robot to strategically induce localized sand avalanches during locomotion and indirectly manipulate obstacles. We conducted 375 trials, systematically varying obstacle spacing, robot orientation, and leg actions in 75 of them. Results show that the movement of closely-spaced obstacles exhibits significant interference, requiring joint modeling. In addition, different multi-leg excavation actions could cause distinct robot state changes, necessitating integrated planning of manipulation and locomotion. To address these challenges, DiffusiveGRAIN includes a diffusion-based environment predictor to capture multi-obstacle movements under granular flow interferences and a robot state predictor to estimate changes in robot state from multi-leg action patterns. Deployment experiments (90 trials) demonstrate that by integrating the environment and robot state predictors, the robot can autonomously plan its movements based on loco-manipulation goals, successfully shifting closely located rocks to desired locations in over 65% of trials. Our study showcases the potential for a locomoting robot to strategically manipulate obstacles to achieve improved mobility on challenging terrains.
Conference on Robot Learning (CoRL), 2025.
|

|
Robot Learning from Any Images
Siheng Zhao*, Jiageng Mao*, Wei Chow, Zeyu Shangguan, Tianheng Shi, Rong Xue, Yuxi Zheng, Yijia Weng, Yang You, Daniel Seita, Leonidas Guibas, Sergey Zakharov, Vitor Campagnolo Guizilini, Yue Wang
@inproceedings{zhao2025RoLA,
title={{Robot Learning from Any Images}},
author={Siheng Zhao and Jiageng Mao and Wei Chow and Zeyu Shangguan and Tianheng Shi and Rong Xue and Yuxi Zheng and Yijia Weng and Yang You and Daniel Seita and Leonidas Guibas and Sergey Zakharov and Vitor Campagnolo Guizilini and Yue Wang},
booktitle={Conference on Robot Learning (CoRL)},
Year={2025}
}
We introduce RoLA, a framework that transforms any in-the-wild image into an interactive, physics-enabled robotic environment. Unlike previous methods, RoLA operates directly on a single image without requiring additional hardware or digital assets. Our framework democratizes robotic data generation by producing massive visuomotor robotic demonstrations within minutes from a wide range of image sources, including camera captures, robotic datasets, and Internet images. At its core, our approach combines a novel method for single-view physical scene recovery with an efficient visual blending strategy for photorealistic data collection. We demonstrate RoLA's versatility across applications like scalable robotic data generation and augmentation, robot learning from Internet images, and single-image real-to-sim-to-real systems for manipulators and humanoids.
Conference on Robot Learning (CoRL), 2025.
|

|
Sequential Multi-Object Grasping with One Dexterous Hand
Sicheng He, Zeyu Shangguan, Kuanning Wang, Yongchong Gu, Yuqian Fu, Yanwei Fu, Daniel Seita
@inproceedings{he2025seqdex,
title={{Sequential Multi-Object Grasping with One Dexterous Hand}},
author={Sicheng He and Zeyu Shangguan and Kuanning Wang and Yongchong Gu and Yuqian Fu and Yanwei Fu and Daniel Seita},
booktitle={International Conference on Intelligent Robots and Systems (IROS)},
Year={2025}
}
Sequentially grasping multiple objects with multi-fingered hands is common in daily life, where humans can fully leverage the dexterity of their hands to enclose multiple objects. However, the diversity of object geometries and the complex contact interactions required for high-DOF hands to grasp one object while enclosing another make sequential multi-object grasping challenging for robots. In this paper, we propose SeqMultiGrasp, a system for sequentially grasping objects with a four-fingered Allegro Hand. We focus on sequentially grasping two objects, ensuring that the hand fully encloses one object before lifting it and then grasps the second object without dropping the first. Our system first synthesizes single-object grasp candidates, where each grasp is constrained to use only a subset of the hand's links. These grasps are then validated in a physics simulator to ensure stability and feasibility. Next, we merge the validated single-object grasp poses to construct multi-object grasp configurations. For real-world deployment, we train a diffusion model conditioned on point clouds to propose grasp poses, followed by a heuristic-based execution strategy. We test our system using 8x8 object combinations in simulation and 6x3 object combinations in real. Our diffusion-based grasp model obtains an average success rate of 65.8% over 1600 simulation trials and 56.7% over 90 real-world trials, suggesting that it is a promising approach for sequential multi-object grasping with multi-fingered hands.
International Conference on Intelligent Robots and Systems (IROS), 2025
|

|
The MOTIF Hand: A Robotic Hand for Multimodal Observations with Thermal, Inertial, and Force Sensors
Hanyang Zhou*, Haozhe Lou*, Wenhao Liu*, Enyu Zhao, Yue Wang, Daniel Seita
@inproceedings{Zhou2025MOTIF,
title={{The MOTIF Hand: A Robotic Hand for Multimodal Observations with Thermal, Inertial, and Force Sensors}},
author={Hanyang Zhou and Haozhe Lou and Wenhao Liu and Enyu Zhao and Yue Wang and Daniel Seita},
booktitle={International Symposium on Experimental Robotics (ISER)},
Year={2025}
}
Advancing dexterous manipulation with multi-fingered robotic hands requires rich sensory capabilities, but existing designs lack onboard thermal and torque sensing. In this work, we propose the MOTIF hand, a novel multimodal and versatile robotic hand that extends the LEAP hand by integrating (i) dense tactile information across the fingers and palm, (ii) a depth sensor, (iii) a thermal camera, (iv), IMU sensors, and (v) a visual sensor. The MOTIF hand is designed to be relatively low-cost (under 4000 USD) and easily reproducible. We also propose experiments to validate our hand design by using it to reconstruct 3D scenes and infer thermal affordances of objects with varying temperatures. Our experiments will demonstrate that the MOTIF hand is a promising approach for the future of dexterous robotic hands with multiple sensors.
International Symposium on Experimental Robotics (ISER), 2025
|

|
HRIBench: Benchmarking Vision-Language Models for Real-Time Human Perception in Human-Robot Interaction
Zhonghao Shi, Enyu Zhao, Nathaniel Dennler, Jingzhen Wang, Xinyang Xu, Kaleen Shrestha, Mengxue Fu, Daniel Seita, Maja Mataric
@inproceedings{Shi2025HRIBench,
title = {{HRIBench: Benchmarking Vision-Language Models for Real-Time Human Perception in Human-Robot Interaction}},
author={Zhonghao Shi and Enyu Zhao and Nathaniel Dennler and Jingzhen Wang and Xinyang Xu and Kaleen Shrestha and Mengxue Fu and Daniel Seita and Maja Mataric},
booktitle={International Symposium on Experimental Robotics (ISER)},
Year = {2025}
}
Real-time human perception is crucial for successful human-robot interaction (HRI). Large vision-language models (VLMs) offer great potential for generalizable perceptual capabilities but often suffer from increased latency, negatively impacting user experience and thus limiting their real-world applicability. To systematically study VLMs' capabilities in human perception for HRI and their performance-latency tradeoff, we introduce HRIBench, a visual question answering (VQA) benchmark designed to evaluate VLMs on a diverse set of human perceptual tasks critical for HRI. HRIBench covers five key domains. (1) non-verbal cue understanding, (2) verbal instruction understanding, (3) human-robot-object relationship understanding, (4) social navigation, and (5) person identification. In this work, we conduct HRI experiments to collect real-world HRI data while also leveraging existing datasets to design new VQA questions for VLM evaluation. Our preliminary results demonstrate that, despite their generalizability, VLMs still struggle with fundamental perceptual skills important for HRI. For the final paper submission, we plan to expand HRIBench to 1,000 VQA questions and conduct a full evaluation of state-of-the-art closed-source and open-source VLMs.
International Symposium on Experimental Robotics (ISER), 2025
|

|
PhysBench: Benchmarking and Enhancing Vision-Language Models for Physical World Understanding
Wei Chow*, Jiageng Mao*, Boyi Li, Daniel Seita, Vitor Campagnolo Guizilini, Yue Wang
@inproceedings{chow2025physbench,
title = {{PhysBench: Benchmarking and Enhancing Vision-Language Models for Physical World Understanding}},
author = {Wei Chow and Jiageng Mao and Boyi Li and Daniel Seita and Vitor Campagnolo Guizilini and Yue Wang},
booktitle = {International Conference on Learning Representations (ICLR)},
Year = {2025}
}
Understanding the physical world is a fundamental challenge in embodied AI, critical for enabling agents to perform complex tasks and operate safely in real-world environments. While Vision-Language Models (VLMs) have shown great promise in reasoning and task planning for embodied agents, their ability to comprehend physical phenomena remains extremely limited. To close this gap, we introduce PhysBench, a comprehensive benchmark designed to evaluate VLMs' physical world understanding capability across a diverse set of tasks. PhysBench contains 100,000 entries of interleaved video-image-text data, categorized into four major domains, physical object properties, physical object relationships, physical scene understanding, and physics-based dynamics, further divided into 19 subclasses and 8 distinct capability dimensions. Our extensive experiments, conducted on 39 representative VLMs, reveal that while these models excel in common-sense reasoning, they struggle with understanding the physical world---likely due to the absence of physical knowledge in their training data and the lack of embedded physical priors. To tackle the shortfall, we introduce PhysAgent, a novel framework that combines the generalization strengths of VLMs with the specialized expertise of vision models, significantly enhancing VLMs' physical understanding across a variety of tasks, including an 18.4% improvement on GPT-4o. Furthermore, our results demonstrate that enhancing VLMs' physical world understanding capabilities can significantly help the deployment of embodied agents, pushing the boundaries of machine intelligence in comprehending and interacting with the physical world. We believe that PhysBench and PhysAgent offer valuable insights and contribute to bridging the gap between VLMs and physical world understanding.
International Conference on Learning Representations (ICLR), 2025 - Oral Presentation (Top 1.8%)
|

|
Cross-domain Multi-modal Few-shot Object Detection via Rich Text
Zeyu Shangguan, Daniel Seita, Mohammad Rostami
@inproceedings{zeyu2025cdmmfsod,
title = {{Cross-domain Multi-modal Few-shot Object Detection via Rich Text}},
author = {Zeyu Shangguan and Daniel Seita and Mohammad Rostami},
booktitle = {IEEE/CVF Winter Conference on Applications of Computer Vision (WACV)},
Year = {2025}
}
Cross-modal feature extraction and integration have led to steady performance improvements in few-shot learning tasks due to generating richer features. However, existing multi-modal object detection (MM-OD) methods degrade when facing significant domain-shift and are sample insufficient. We hypothesize that rich text information could more effectively help the model to build a knowledge relationship between the vision instance and its language description and can help mitigate domain shift. Specifically, we study the Cross-Domain few-shot generalization of MM-OD (CDMM-FSOD) and propose a meta-learning based multi-modal few-shot object detection method that utilizes rich text semantic information as an auxiliary modality to achieve domain adaptation in the context of FSOD. Our proposed network contains (i) a multi-modal feature aggregation module that aligns the vision and language support feature embeddings and (ii) a rich text semantic rectify module that utilizes bidirectional text feature generation to reinforce multi-modal feature alignment and thus to enhance the model's language understanding capability. We evaluate our model on common standard cross-domain object detection datasets and demonstrate that our approach considerably outperforms existing FSOD methods.
IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 2025
|

|
Learning to Singulate Objects in Packed Environments using a Dexterous Hand
Hao Jiang, Yuhai Wang†, Hanyang Zhou†, Daniel Seita
@inproceedings{Hao2024SopeDex,
title = {{Learning to Singulate Objects in Packed Environments using a Dexterous Hand}},
author = {Hao Jiang and Yuhai Wang and Hanyang Zhou and Daniel Seita},
booktitle = {International Symposium of Robotics Research (ISRR)},
Year = {2024}
}
Robotic object singulation, where a robot must isolate, grasp, and retrieve a target object in a cluttered environment, is a fundamental challenge in robotic manipulation. This task is difficult due to occlusions and how other objects act as obstacles for manipulation. A robot must also reason about the effect of object-object interactions as it tries to singulate the target. Prior work has explored object singulation in scenarios where there is enough free space to perform relatively long pushes to separate objects, in contrast to when space is tight and objects have little separation from each other. In this paper, we propose the Singulating Objects in Packed Environments (SOPE) framework. We propose a novel method that involves a displacement-based state representation and a multi-phase reinforcement learning procedure that enables singulation using the 16-DOF Allegro Hand. We demonstrate extensive experiments in Isaac Gym simulation, showing the ability of our system to singulate a target object in clutter. We directly transfer the policy trained in simulation to the real world. Over 250 physical robot manipulation trials, our method obtains success rates of 79.2%, outperforming alternative learning and non-learning methods.
International Symposium of Robotics Research (ISRR), 2024
|

|
GPT-Fabric: Smoothing and Folding Fabric by Leveraging Pre-Trained Foundation Models
Vedant Raval*, Enyu Zhao*, Hejia Zhang, Stefanos Nikolaidis, Daniel Seita
@inproceedings{raval2024gptfabric,
title = {{GPT-Fabric: Smoothing and Folding Fabric by Leveraging Pre-Trained Foundation Models}},
author = {Vedant Raval and Enyu Zhao and Hejia Zhang and Stefanos Nikolaidis and Daniel Seita},
booktitle = {International Symposium of Robotics Research (ISRR)},
Year = {2024}
}
Fabric manipulation has applications in folding blankets, handling patient clothing, and protecting items with covers. It is challenging for robots to perform fabric manipulation since fabrics have infinite-dimensional configuration spaces, complex dynamics, and may be in folded or crumpled configurations with severe self-occlusions. Prior work on robotic fabric manipulation relies either on heavily engineered setups or learning-based approaches that create and train on robot-fabric interaction data. In this paper, we propose GPT-Fabric for the canonical tasks of fabric smoothing and folding, where GPT directly outputs an action informing a robot where to grasp and pull a fabric. We perform extensive experiments in simulation to test GPT-Fabric against prior state of the art methods for smoothing and folding. We obtain comparable or better performance to most methods even without explicitly training on a fabric-specific dataset (i.e., zero-shot manipulation). Furthermore, we apply GPT-Fabric in physical experiments over 10 smoothing and 12 folding rollouts. Our results suggest that GPT-Fabric is a promising approach for high-precision fabric manipulation tasks.
International Symposium of Robotics Research (ISRR), 2024
|

|
Learning Granular Media Avalanche Behavior for Indirectly Manipulating Obstacles on a Granular Slope
Haodi Hu, Feifei Qian†, Daniel Seita†
@inproceedings{hu2024grain,
title = {{Learning Granular Media Avalanche Behavior for Indirectly Manipulating Obstacles on a Granular Slope}},
author = {Haodi Hu and Feifei Qian and Daniel Seita},
booktitle = {Conference on Robot Learning (CoRL)},
Year = {2024}
}
Legged robot locomotion on sand slopes is challenging due to the complex dynamics of granular media and how the lack of solid surfaces can hinder locomotion. A promising strategy, inspired by ghost crabs and other organisms in nature, is to strategically interact with rocks, debris, and other obstacles to facilitate movement. To provide legged robots with this ability, we present a novel approach that leverages avalanche dynamics to indirectly manipulate objects on a granular slope. We use a Vision Transformer (ViT) to process image representations of granular dynamics and robot excavation actions. The ViT predicts object movement, which we use to determine which leg excavation action to execute. We collect training data from 100 real physical trials and, at test time, deploy our trained model in novel settings. Experimental results suggest that our model can accurately predict object movements and achieve a success rate ≥80% in a variety of manipulation tasks with up to four obstacles, and can also generalize to objects with different physics properties. To our knowledge, this is the first paper to leverage granular media avalanche dynamics to indirectly manipulate objects on granular slopes.
Conference on Robot Learning (CoRL), 2024
|

|
VoxAct-B: Voxel-Based Acting and Stabilizing Policy for Bimanual Manipulation
I-Chun Arthur Liu, Sicheng He, Daniel Seita†, Gaurav Sukhatme†
@inproceedings{liu2024voxactb,
title = {{VoxAct-B: Voxel-Based Acting and Stabilizing Policy for Bimanual Manipulation}},
author = {I-Chun Arthur Liu and Sicheng He and Daniel Seita and Gaurav Sukhatme},
booktitle = {Conference on Robot Learning (CoRL)},
Year = {2024}
}
Bimanual manipulation is critical to many robotics applications. In contrast to single-arm manipulation, bimanual manipulation tasks are challenging due to higher-dimensional action spaces. Prior works leverage large amounts of data and primitive actions to address this problem, but may suffer from sample inefficiency and limited generalization across various tasks. To this end, we propose VoxAct-B, a language-conditioned, voxel-based method that leverages Vision Language Models (VLMs) to prioritize key regions within the scene and reconstruct a voxel grid. We provide this voxel grid to our bimanual manipulation policy to learn acting and stabilizing actions. This approach enables more efficient policy learning from voxels and is generalizable to different tasks. In simulation, we show that VoxAct-B outperforms strong baselines on fine-grained bimanual manipulation tasks. Furthermore, we demonstrate VoxAct-B on real-world Open Drawer and Open Jar tasks using two UR5s.
Conference on Robot Learning (CoRL), 2024
|

|
Bagging by Learning to Singulate Layers Using Interactive Perception
Lawrence Yunliang Chen, Baiyu Shi, Roy Lin, Daniel Seita, Ayah Ahmad, Richard Cheng, Thomas Kollar, David Held, Ken Goldberg
@inproceedings{slipbagging2023,
title={{Bagging by Learning to Singulate Layers Using Interactive Perception}},
author={Lawrence Yunliang Chen and Baiyu Shi and Roy Lin and Daniel Seita and Ayah Ahmad and Richard Cheng and Thomas Kollar and David Held and Ken Goldberg},
booktitle={International Conference on Intelligent Robots and Systems (IROS)},
year={2023}
}
Many fabric handling and 2D deformable material tasks in homes and industry require singulating layers of material such as opening a bag or arranging garments for sewing. In contrast to methods requiring specialized sensing or end effectors, we use only visual observations with ordinary parallel jaw grippers. We propose SLIP, Singulating Layers using Interactive Perception, and apply SLIP to the task of autonomous bagging. We develop SLIP-Bagging, a bagging algorithm that manipulates a plastic or fabric bag from an unstructured state, and uses SLIP to grasp the top layer of the bag to open it for object insertion. In physical experiments, a YuMi robot achieves a success rate of 67% to 81% across bags of a variety of materials, shapes, and sizes, significantly improving in success rate and generality over prior work. Experiments also suggest that SLIP can be applied to tasks such as singulating layers of folded cloth and garments.
International Conference on Intelligent Robots and Systems (IROS), 2023
|

|
AutoBag: Learning to Open Plastic Bags and Insert Objects
Lawrence Yunliang Chen, Baiyu Shi, Daniel Seita, Richard Cheng, Thomas Kollar, David Held, Ken Goldberg
@inproceedings{autobag2023,
title={{AutoBag: Learning to Open Plastic Bags and Insert Objects}},
author={Lawrence Yunliang Chen and Baiyu Shi and Daniel Seita and Richard Cheng and Thomas Kollar and David Held and Ken Goldberg and Ken Goldberg and Ken Goldberg and Ken Goldberg and Ken Goldberg and Ken Goldberg},
booktitle={International Conference on Robotics and Automation (ICRA)},
year={2023}
}
Thin plastic bags are ubiquitous in retail stores, healthcare, food handling, recycling, homes, and school lunchrooms. They are challenging both for perception (due to specularities and occlusions) and for manipulation (due to the dynamics of their 3D deformable structure). We formulate the task of manipulating common plastic shopping bags with two handles from an unstructured initial state to a state where solid objects can be inserted into the bag for transport. We propose a self-supervised learning framework where a dual-arm robot learns to recognize the handles and rim of plastic bags using UV-fluorescent markings; at execution time, the robot does not use UV markings or UV light. We propose Autonomous Bagging (AutoBag), where the robot uses the learned perception model to open plastic bags through iterative manipulation. We present novel metrics to evaluate the quality of a bag state and new motion primitives for reorienting and opening bags from visual observations. In physical experiments, a YuMi robot using AutoBag is able to open bags and achieve a success rate of 16/30 for inserting at least one item across a variety of initial bag configurations
International Conference on Robotics and Automation (ICRA), 2023
|

|
ToolFlowNet: Robotic Manipulation with Tools via Predicting Tool Flow from Point Clouds
Daniel Seita, Yufei Wang†, Sarthak J Shetty†, Edward Yao Li†, Zackory Erickson, David Held
Conference on Robot Learning (CoRL), 2022
|

|
Learning to Singulate Layers of Cloth Using Tactile Feedback
Sashank Tirumala*, Thomas Weng*, Daniel Seita*, Oliver Kroemer, Zeynep Temel, David Held
@inproceedings{tirumala2022reskin,
title={{Learning to Singulate Layers of Cloth using Tactile Feedback}},
author={Tirumala, Sashank and Weng, Thomas and Seita, Daniel and Kroemer, Oliver and Temel, Zeynep and Held, David},
booktitle={International Conference on Intelligent Robots and Systems (IROS)},
year={2022}
}
Robotic manipulation of cloth has applications ranging from fabrics manufacturing to handling blankets and laundry. Cloth manipulation is challenging for robots largely due to their high degrees of freedom, complex dynamics, and severe self-occlusions when in folded or crumpled configurations. Prior work on robotic manipulation of cloth relies primarily on vision sensors alone, which may pose challenges for fine-grained manipulation tasks such as grasping a desired number of cloth layers from a stack of cloth. In this paper, we propose to use tactile sensing for cloth manipulation; we attach a tactile sensor (ReSkin) to one of the two fingertips of a Franka robot and train a classifier to determine whether the robot is grasping a specific number of cloth layers. During test-time experiments, the robot uses this classifier as part of its policy to grasp one or two cloth layers using tactile feedback to determine suitable grasping points. Experimental results over 180 physical trials suggest that the proposed method outperforms baselines that do not use tactile feedback and has a better generalization to unseen fabrics compared to methods that use image classifiers.
International Conference on Intelligent Robots and Systems (IROS), 2022 - Best Paper at ROMADO-SI
|

|
Efficiently Learning Single-Arm Fling Motions to Smooth Garments
Lawrence Yunliang Chen*, Huang Huang*, Ellen Novoseller, Daniel Seita, Jeffrey Ichnowski, Michael Laskey, Richard Cheng, Thomas Kollar, Ken Goldberg
@inproceedings{flinging_2022,
title={{Efficiently Learning Single-Arm Fling Motions to Smooth Garments}},
author={Lawrence Yunliang Chen and Huang Huang and Ellen Novoseller and Daniel Seita and Jeffrey Ichnowski and Michael Laskey and Richard Cheng and Thomas Kollar and Ken Goldberg},
booktitle={International Symposium on Robotics Research (ISRR)},
Year={2022}
}
Recent work has shown that 2-arm 'fling' motions can be effective for garment smoothing. We consider single-arm fling motions. Unlike 2-arm fling motions, which require little robot trajectory parameter tuning, single-arm fling motions are very sensitive to trajectory parameters. We consider a single 6-DOF robot arm that learns fling trajectories to achieve high garment coverage. Given a garment grasp point, the robot explores different parameterized fling trajectories in physical experiments. To improve learning efficiency, we propose a coarse-to-fine learning method that first uses a multi-armed bandit (MAB) framework to efficiently find a candidate fling action, which it then refines via a continuous optimization method. Further, we propose novel training and execution-time stopping criteria based on fling outcome uncertainty; the training-time stopping criterion increases data efficiency while the execution-time stopping criteria leverage repeated fling actions to increase performance. Compared to baselines, the proposed method significantly accelerates learning. Moreover, with prior experience on similar garments collected through self-supervision, the MAB learning time for a new garment is reduced by up to 87%. We evaluate on 36 real garments: towels, T-shirts, long-sleeve shirts, dresses, sweat pants, and jeans. Results suggest that using prior experience, a robot requires under 30 minutes to learn a fling action for a novel garment that achieves 60-94% coverage.
International Symposium on Robotics Research (ISRR), 2022
|

|
Automating Surgical Peg Transfer: Calibration with Deep Learning Can Exceed Speed, Accuracy, and Consistency of Humans
Minho Hwang, Jeffrey Ichnowski, Brijen Thananjeyan, Daniel Seita, Samuel Paradis, Danyal Fer, Thomas Low, Ken Goldberg
@inproceedings{minho_superhuman_2022,
title = {{Automating Surgical Peg Transfer: Calibration with Deep Learning Can Exceed Speed, Accuracy, and Consistency of Humans}},
author = {Minho Hwang and Jeffrey Ichnowski and Brijen Thananjeyan and Daniel Seita and Samuel Paradis and Danyal Fer and Thomas Low and Ken Goldberg},
booktitle = {IEEE Transactions on Automation Science and Engineering (TASE)},
Year = {2022}
}
Peg transfer is a well-known surgical training task in the Fundamentals of Laparoscopic Surgery (FLS). While human surgeons teleoperate robots such as the da Vinci to perform this task with high speed and accuracy, it is challenging to automate. This paper presents a novel system and control method using a da Vinci Research Kit (dVRK) surgical robot and a Zivid depth sensor, and a human subjects study comparing performance on three variants of the peg-transfer task: unilateral, bilateral without handovers, and bilateral with handovers. The system combines 3D printing, depth sensing, and deep learning for calibration with a new analytic inverse kinematics model and a time-minimized motion controller. In a controlled study of 3384 peg transfer trials performed by the system, an expert surgical resident, and 9 volunteers, results suggest that the system achieves accuracy on par with the experienced surgical resident and is significantly faster and more consistent than the surgical resident and volunteers. The system also exhibits the highest consistency and lowest collision rate. To our knowledge, this is the first autonomous system to achieve superhuman performance on a standardized surgical task.
Transactions on Automation Science and Engineering (T-ASE), 2022
|

|
Planar Robot Casting with Real2Sim2Real Self-Supervised Learning
Vincent Lim*, Huang Huang*, Yunliang Chen, Jonathan Wang, Jeffrey Ichnowski, Daniel Seita, Michael Laskey, Ken Goldberg
@inproceedings{lim2022planar,
title = {{Planar Robot Casting with Real2Sim2Real Self-Supervised Learning}},
author = {Vincent Lim and Huang Huang and Lawrence Yunliang Chen and Jonathan Wang and Jeffrey Ichnowski and Daniel Seita and Michael Laskey and Ken Goldberg},
booktitle = {IEEE International Conference on Robotics and Automation (ICRA)},
year = {2022}
}
This paper introduces the task of Planar Robot Casting (PRC): where one planar motion of a robot arm holding one end of a cable causes the other end to slide across the plane toward a desired target. PRC allows the cable to reach points beyond the robot workspace and has applications for cable management in homes, warehouses, and factories. To efficiently learn a PRC policy for a given cable, we propose Real2Sim2Real, a self-supervised framework that automatically collects physical trajectory examples to tune parameters of a dynamics simulator using Differential Evolution, generates many simulated examples, and then learns a policy using a weighted combination of simulated and physical data. We evaluate Real2Sim2Real with three simulators, Isaac Gym-segmented, Isaac Gym-hybrid, and PyBullet, two function approximators, Gaussian Processes and Neural Networks (NNs), and three cables with differing stiffness, torsion, and friction. Results with 240 physical trials suggest that the PRC policies can attain median error distance (as % of cable length) ranging from 8% to 14%, outperforming baselines and policies trained on only real or only simulated examples.
International Conference on Robotics and Automation (ICRA), 2022
|

|
VisuoSpatial Foresight for Physical Sequential Fabric Manipulation
Ryan Hoque*, Daniel Seita*, Ashwin Balakrishna, Aditya Ganapathi, Ajay Tanwani, Nawid Jamali, Katsu Yamane, Soshi Iba, Ken Goldberg
@article{fabric_vsf_2021,
title = {{VisuoSpatial Foresight for Physical Sequential Fabric Manipulation}},
author = {Ryan Hoque and Daniel Seita and Ashwin Balakrishna and Aditya Ganapathi and Ajay Tanwani and Nawid Jamali and Katsu Yamane and Soshi Iba and Ken Goldberg},
journal = {arXiv preprint arXiv:2102.09754},
Year = {2021}
}
Robotic fabric manipulation has applications in home robotics, textiles, senior care and surgery. Existing fabric manipulation techniques, however, are designed for specific tasks, making it difficult to generalize across different but related tasks. We build upon the Visual Foresight framework to learn fabric dynamics that can be efficiently reused to accomplish different sequential fabric manipulation tasks with a single goal-conditioned policy. We extend our earlier work on VisuoSpatial Foresight (VSF), which learns visual dynamics on domain randomized RGB images and depth maps simultaneously and completely in simulation. In this earlier work, we evaluated VSF on multi-step fabric smoothing and folding tasks against 5 baseline methods in simulation and on the da Vinci Research Kit (dVRK) surgical robot without any demonstrations at train or test time. A key finding was that depth sensing significantly improves performance: RGBD data yields an 80% improvement in fabric folding success rate in simulation over pure RGB data. In this work, we vary 4 components of VSF, including data generation, visual dynamics model, cost function, and optimization procedure. Results suggest that training visual dynamics models using longer, corner-based actions can improve the efficiency of fabric folding by 76% and enable a physical sequential fabric folding task that VSF could not previously perform with 90% reliability.
Autonomous Robots (AURO), 2021
|

|
LazyDAgger: Reducing Context Switching in Interactive Imitation Learning
Ryan Hoque, Ashwin Balakrishna, Carl Putterman, Michael Luo, Daniel Brown, Daniel Seita, Brijen Thananjeyan, Ellen Novoseller, Ken Goldberg
@inproceedings{lazydagger_2021,
title = {{LazyDAgger: Reducing Context Switching in Interactive Imitation Learning}},
author = {Ryan Hoque and Ashwin Balakrishna and Carl Putterman and Michael Luo and Daniel S. Brown and Daniel Seita and Brijen Thananjeyan and Ellen Novoseller and Ken Goldberg},
booktitle = {IEEE International Conference on Automation Science and Engineering (CASE)},
Year = {2021}
}
Corrective interventions while a robot is learning to automate a task provide an intuitive method for a human supervisor to assist the robot and convey information about desired behavior. However, these interventions can impose significant burden on a human supervisor, as each intervention interrupts other work the human is doing, incurs latency with each context switch between supervisor and autonomous control, and requires time to perform. We present LazyDAgger, which extends the interactive imitation learning (IL) algorithm SafeDAgger to reduce context switches between supervisor and autonomous control. We find that LazyDAgger improves the performance and robustness of the learned policy during both learning and execution while limiting burden on the supervisor. Simulation experiments suggest that LazyDAgger can reduce context switches by an average of 60% over SafeDAgger on 3 continuous control tasks while maintaining state-of-the-art policy performance. In physical fabric manipulation experiments with an ABB YuMi robot, LazyDAgger reduces context switches by 60% while achieving a 60% higher success rate than SafeDAgger at execution time.
International Conference on Automation Science and Engineering (CASE), 2021
|
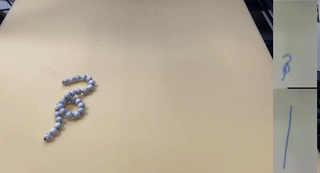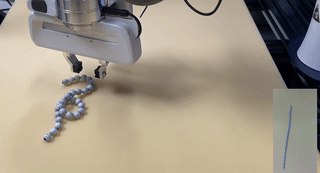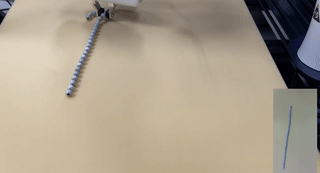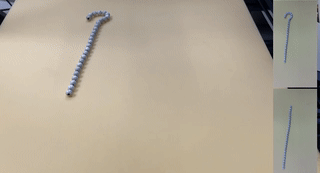
|
Learning to Rearrange Deformable Cables, Fabrics, and Bags with Goal-Conditioned Transporter Networks
Daniel Seita, Pete Florence, Jonathan Tompson, Erwin Coumans, Vikas Sindhwani, Ken Goldberg, Andy Zeng
@inproceedings{seita_bags_2021,
title = {{Learning to Rearrange Deformable Cables, Fabrics, and Bags with Goal-Conditioned Transporter Networks}},
author = {Daniel Seita and Pete Florence and Jonathan Tompson and Erwin Coumans and Vikas Sindhwani and Ken Goldberg and Andy Zeng},
booktitle = {IEEE International Conference on Robotics and Automation (ICRA)},
Year = {2021}
}
Rearranging and manipulating deformable objects such as cables, fabrics, and bags is a long-standing challenge in robotic manipulation. The complex dynamics and high-dimensional configuration spaces of deformables, compared to rigid objects, make manipulation difficult not only for multi-step planning, but even for goal specification. Goals cannot be as easily specified as rigid object poses, and may involve complex relative spatial relations such as 'place the item inside the bag'. In this work, we develop a suite of simulated benchmarks with 1D, 2D, and 3D deformable structures, including tasks that involve image-based goal-conditioning and multi-step deformable manipulation. We propose embedding goal-conditioning into Transporter Networks, a recently proposed model architecture for learning robotic manipulation that rearranges deep features to infer displacements that can represent pick and place actions. In simulation and in physical experiments, we demonstrate that goal-conditioned Transporter Networks enable agents to manipulate deformable structures into flexibly specified configurations without test-time visual anchors for target locations. We also significantly extend prior results using Transporter Networks for manipulating deformable objects by testing on tasks with 2D and 3D deformables.
International Conference on Robotics and Automation (ICRA), 2021
|

|
Robots of the Lost Arc: Self-Supervised Learning to Dynamically Manipulate Fixed-Endpoint Cables
Harry Zhang, Jeffrey Ichnowski, Daniel Seita, Jonathan Wang, Huang Huang, Ken Goldberg
@inproceedings{harry_rope_2021,
title = {{Robots of the Lost Arc: Self-Supervised Learning to Dynamically Manipulate Fixed-Endpoint Cables}},
author = {Harry Zhang and Jeff Ichnowski and Daniel Seita and Jonathan Wang and Huang Huang and Ken Goldberg},
booktitle = {IEEE International Conference on Robotics and Automation (ICRA)},
Year = {2021}
}
We explore how high-speed robot arm motions can dynamically manipulate cables to vault over obstacles, knock objects from pedestals, and weave between obstacles. In this paper, we propose a self-supervised learning framework that enables a UR5 robot to perform these three tasks. The framework finds a 3D apex point for the robot arm, which, together with a task-specific trajectory function, defines an arcing motion that dynamically manipulates the cable to perform tasks with varying obstacle and target locations. The trajectory function computes minimum-jerk motions that are constrained to remain within joint limits and to travel through the 3D apex point by repeatedly solving quadratic programs to find the shortest and fastest feasible motion. We experiment with 5 physical cables with different thickness and mass and compare performance against two baselines in which a human chooses the apex point. Results suggest that a baseline with a fixed apex across the three tasks achieves respective success rates of 51.7%, 36.7%, and 15.0%, and a baseline with human-specified, task-specific apex points achieves 66.7%, 56.7%, and 15.0% success rate respectively, while the robot using the learned apex point can achieve success rates of 81.7% in vaulting, 65.0% in knocking, and 60.0% in weaving.
International Conference on Robotics and Automation (ICRA), 2021
|

|
Learning Dense Visual Correspondences in Simulation to Smooth and Fold Real Fabrics
Aditya Ganapathi, Priya Sundaresan, Brijen Thananjeyan, Ashwin Balakrishna, Daniel Seita, Jennifer Grannen, Minho Hwang, Ryan Hoque, Joseph Gonzalez, Nawid Jamali, Katsu Yamane, Soshi Iba, Ken Goldberg
@inproceedings{descriptors_fabrics_2021,
title = {{Learning Dense Visual Correspondences in Simulation to Smooth and Fold Real Fabrics}},
author = {Aditya Ganapathi and Priya Sundaresan and Brijen Thananjeyan and Ashwin Balakrishna and Daniel Seita and Jennifer Grannen and Minho Hwang and Ryan Hoque and Joseph Gonzalez and Nawid Jamali and Katsu Yamane and Soshi Iba and Ken Goldberg},
booktitle = {IEEE International Conference on Robotics and Automation (ICRA)},
Year = {2021}
}
Robotic fabric manipulation is challenging due to the infinite dimensional configuration space, self-occlusion, and complex dynamics of fabrics. There has been significant prior work on learning policies for specific deformable manipulation tasks, but comparatively less focus on algorithms which can efficiently learn many different tasks. In this paper, we learn visual correspondences for deformable fabrics across different configurations in simulation and show that this representation can be used to design policies for a variety of tasks. Given a single demonstration of a new task from an initial fabric configuration, the learned correspondences can be used to compute geometrically equivalent actions in a new fabric configuration. This makes it possible to robustly imitate a broad set of multi-step fabric smoothing and folding tasks on multiple physical robotic systems. The resulting policies achieve 80.3% average task success rate across 10 fabric manipulation tasks on two different robotic systems, the da Vinci surgical robot and the ABB YuMi. Results also suggest robustness to fabrics of various colors, sizes, and shapes.
International Conference on Robotics and Automation (ICRA), 2021
|

|
Intermittent Visual Servoing: Efficiently Learning Policies Robust to Tool Changes for High-precision Surgical Manipulation
Samuel Paradis, Minho Hwang, Brijen Thananjeyan, Jeffrey Ichnowski, Daniel Seita, Danyal Fer, Thomas Low, Joseph E. Gonzalez, Ken Goldberg
@inproceedings{sam_ivs_2021,
title = {{Intermittent Visual Servoing: Efficiently Learning Policies Robust to Instrument Changes for High-precision Surgical Manipulation}},
author = {Samuel Paradis and Minho Hwang and Brijen Thananjeyan and Jeffrey Ichnowski and Daniel Seita and Danyal Fer and Thomas Low and Joseph E. Gonzalez and Ken Goldberg},
booktitle = {IEEE International Conference on Robotics and Automation (ICRA)},
Year = {2021}
}
Automation of surgical tasks using cable-driven robots is challenging due to backlash, hysteresis, and cable tension, and these issues are exacerbated as surgical instruments must often be changed during an operation. In this work, we propose a framework for automation of high-precision surgical tasks by learning sample efficient, accurate, closed-loop policies that operate directly on visual feedback instead of robot encoder estimates. This framework, which we call intermittent visual servoing (IVS), intermittently switches to a learned visual servo policy for high-precision segments of repetitive surgical tasks while relying on a coarse open-loop policy for the segments where precision is not necessary. To compensate for cable-related effects, we apply imitation learning to rapidly train a policy that maps images of the workspace and instrument from a top-down RGB camera to small corrective motions. We train the policy using only 180 human demonstrations that are roughly 2 seconds each. Results on a da Vinci Research Kit suggest that combining the coarse policy with half a second of corrections from the learned policy during each high-precision segment improves the success rate on the Fundamentals of Laparoscopic Surgery peg transfer task from 72.9% to 99.2%, 31.3% to 99.2%, and 47.2% to 100.0% for 3 instruments with differing cable-related effects. In the contexts we studied, IVS attains the highest published success rates for automated surgical peg transfer and is significantly more reliable than previous techniques when instruments are changed.
International Conference on Robotics and Automation (ICRA), 2021
|

|
Deep Imitation Learning of Sequential Fabric Smoothing From an Algorithmic Supervisor
Daniel Seita, Aditya Ganapathi, Ryan Hoque, Minho Hwang, Edward Cen, Ajay Kumar Tanwani, Ashwin Balakrishna, Brijen Thananjeyan, Jeffrey Ichnowski, Nawid Jamali, Kastu Yamane, Soshi Iba, John Canny, Ken Goldberg
@inproceedings{seita_fabrics_2020,
title = {{Deep Imitation Learning of Sequential Fabric Smoothing From an Algorithmic Supervisor}},
author = {Daniel Seita and Aditya Ganapathi and Ryan Hoque and Minho Hwang and Edward Cen and Ajay Kumar Tanwani and Ashwin Balakrishna and Brijen Thananjeyan and Jeffrey Ichnowski and Nawid Jamali and Katsu Yamane and Soshi Iba and John Canny and Ken Goldberg},
booktitle = {IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)},
Year = {2020}
}
Sequential pulling policies to flatten and smooth fabrics have applications from surgery to manufacturing to home tasks such as bed making and folding clothes. Due to the complexity of fabric states and dynamics, we apply deep imitation learning to learn policies that, given color (RGB), depth (D), or combined color-depth (RGBD) images of a rectangular fabric sample, estimate pick points and pull vectors to spread the fabric to maximize coverage. To generate data, we develop a fabric simulator and an algorithmic supervisor that has access to complete state information. We train policies in simulation using domain randomization and dataset aggregation (DAgger) on three tiers of difficulty in the initial randomized configuration. We present results comparing five baseline policies to learned policies and report systematic comparisons of RGB vs D vs RGBD images as inputs. In simulation, learned policies achieve comparable or superior performance to analytic baselines. In 180 physical experiments with the da Vinci Research Kit (dVRK) surgical robot, RGBD policies trained in simulation attain coverage of 83% to 95% depending on difficulty tier, suggesting that effective fabric smoothing policies can be learned from an algorithmic supervisor and that depth sensing is a valuable addition to color alone.
International Conference on Intelligent Robots and Systems (IROS), 2020
|

|
Efficiently Calibrating Cable-Driven Surgical Robots with RGBD Fiducial Sensing and Recurrent Neural Networks
Minho Hwang, Brijen Thananjeyan, Samuel Paradis, Daniel Seita, Jeffrey Ichnowski, Danyal Fer, Thomas Low, Ken Goldberg
@inproceedings{minho_calibration_2020,
title = {{Efficiently Calibrating Cable-Driven Surgical Robots with RGBD Fiducial Sensing and Recurrent Neural Networks}},
author = {Minho Hwang and Brijen Thananjeyan and Samuel Paradis and Daniel Seita and Jeffrey Ichnowski and Danyal Fer and Thomas Low and Ken Goldberg},
booktitle = {IEEE Robotics and Automation Letters (RA-L)},
Year = {2020}
}
Automation of surgical subtasks using cable-driven robotic surgical assistants (RSAs) such as Intuitive Surgical's da Vinci Research Kit (dVRK) is challenging due to imprecision in control from cable-related effects such as cable stretching and hysteresis. We propose a novel approach to efficiently calibrate such robots by placing a 3D printed fiducial coordinate frames on the arm and end-effector that is tracked using RGBD sensing. To measure the coupling and history-dependent effects between joints, we analyze data from sampled trajectories and consider 13 approaches to modeling. These models include linear regression and LSTM recurrent neural networks, each with varying temporal window length to provide compensatory feedback. With the proposed method, data collection of 1800 samples takes 31 minutes and model training takes under 1 minute. Results on a test set of reference trajectories suggest that the trained model can reduce the mean tracking error of the physical robot from 2.96 mm to 0.65 mm. Results on the execution of open-loop trajectories of the FLS peg transfer surgeon training task suggest that the best model increases success rate from 39.4% to 96.7%, producing performance comparable to that of an expert surgical resident.
Robotics and Automation Letters (RA-L), 2020
|

|
VisuoSpatial Foresight for Multi-Step, Multi-Task Fabric Manipulation
Ryan Hoque*, Daniel Seita*, Ashwin Balakrishna, Aditya Ganapathi, Ajay Tanwani, Nawid Jamali, Katsu Yamane, Soshi Iba, Ken Goldberg
Robotics: Science and Systems (RSS), 2020
|

|
Applying Depth-Sensing to Automated Surgical Manipulation with a da Vinci Robot
Minho Hwang*, Daniel Seita*, Brijen Thananjeyan, Jeff Ichnowski, Samuel Paradis, Danyal Fer, Thomas Low, Ken Goldberg
@inproceedings{minho_pegs_2020,
title = {{Applying Depth-Sensing to Automated Surgical Manipulation with a da Vinci Robot}},
author = {Minho Hwang and Daniel Seita and Brijen Thananjeyan and Jeffrey Ichnowski and Samuel Paradis and Danyal Fer and Thomas Low and Ken Goldberg},
booktitle = {International Symposium on Medical Robotics (ISMR)},
Year = {2020}
}
Recent advances in depth-sensing have significantly increased accuracy, resolution, and frame rate, as shown in the 1920x1200 resolution and 13 frames per second Zivid RGBD camera. In this study, we explore the potential of depth sensing for efficient and reliable automation of surgical subtasks. We consider a monochrome (all red) version of the peg transfer task from the Fundamentals of Laparoscopic Surgery training suite implemented with the da Vinci Research Kit (dVRK). We use calibration techniques that allow the imprecise, cable-driven da Vinci to reduce error from 4-5 mm to 1-2 mm in the task space. We report experimental results for a handover-free version of the peg transfer task, performing 20 and 5 physical episodes with single- and bilateral-arm setups, respectively. Results over 236 and 49 total block transfer attempts for the single- and bilateral-arm peg transfer cases suggest that reliability can be attained with 86.9 % and 78.0 % for each individual block, with respective block transfer speeds of 10.02 and 5.72 seconds.
International Symposium on Medical Robotics (ISMR), 2020
|

|
Deep Transfer Learning of Pick Points on Fabric for Robot Bed-Making
Daniel Seita*, Nawid Jamali*, Michael Laskey*, Ron Berenstein, Ajay Tanwani, Prakash Baskaran, Soshi Iba, John Canny, Ken Goldberg
@inproceedings{seita_bedmake_2019,
title = {{Deep Transfer Learning of Pick Points on Fabric for Robot Bed-Making}},
author = {Daniel Seita and Nawid Jamali and Michael Laskey and Ron Berenstein and Ajay Kumar Tanwani and Prakash Baskaran and Soshi Iba and John Canny and Ken Goldberg},
booktitle = {International Symposium on Robotics Research (ISRR)},
Year = {2019}
}
A fundamental challenge in manipulating fabric for clothes folding and textiles manufacturing is computing 'pick points' to effectively modify the state of an uncertain manifold. We present a supervised deep transfer learning approach to locate pick points using depth images for invariance to color and texture. We consider the task of bed-making, where a robot sequentially grasps and pulls at pick points to increase blanket coverage. We perform physical experiments with two mobile manipulator robots, the Toyota HSR and the Fetch, and three blankets of different colors and textures. We compare coverage results from (1) human supervision, (2) a baseline of picking at the uppermost blanket point, and (3) learned pick points. On a quarter-scale twin bed, a model trained with combined data from the two robots achieves 92% blanket coverage compared with 83% for the baseline and 95% for human supervisors. The model transfers to two novel blankets and achieves 93% coverage. Average coverage results of 92% for 193 beds suggest that transfer-invariant robot pick points on fabric can be effectively learned.
International Symposium on Robotics Research (ISRR), 2019
|
|
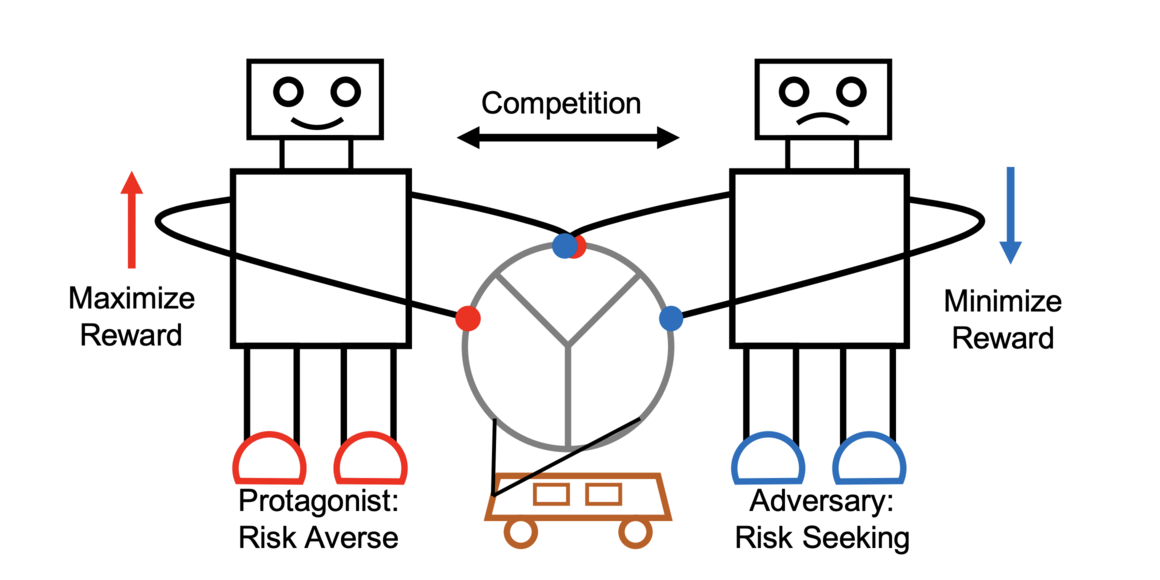
Risk Averse Robust Adversarial Reinforcement Learning
Xinlei Pan, Daniel Seita, Yang Gao, John Canny
@inproceedings{xinlei_icra_2019,
title = {{Risk Averse Robust Adversarial Reinforcement Learning}},
author = {Xinlei Pan and Daniel Seita and Yang Gao and John Canny},
booktitle = {IEEE International Conference on Robotics and Automation (ICRA)},
Year = {2019}
}
Deep reinforcement learning has recently made significant progress in solving computer games and robotic control tasks. A known problem, though, is that policies overfit to the training environment and may not avoid rare, catastrophic events such as automotive accidents. A classical technique for improving the robustness of reinforcement learning algorithms is to train on a set of randomized environments, but this approach only guards against common situations. Recently, robust adversarial reinforcement learning (RARL) was developed, which allows efficient applications of random and systematic perturbations by a trained adversary. A limitation of RARL is that only the expected control objective is optimized; there is no explicit modeling or optimization of risk. Thus the agents do not consider the probability of catastrophic events (i.e., those inducing abnormally large negative reward), except through their effect on the expected objective. In this paper we introduce risk-averse robust adversarial reinforcement learning (RARARL), using a risk-averse protagonist and a risk-seeking adversary. We test our approach on a self-driving vehicle controller. We use an ensemble of policy networks to model risk as the variance of value functions. We show through experiments that a risk-averse agent is better equipped to handle a risk-seeking adversary, and experiences substantially fewer crashes compared to agents trained without an adversary.
International Conference on Robotics and Automation (ICRA), 2019
|
|
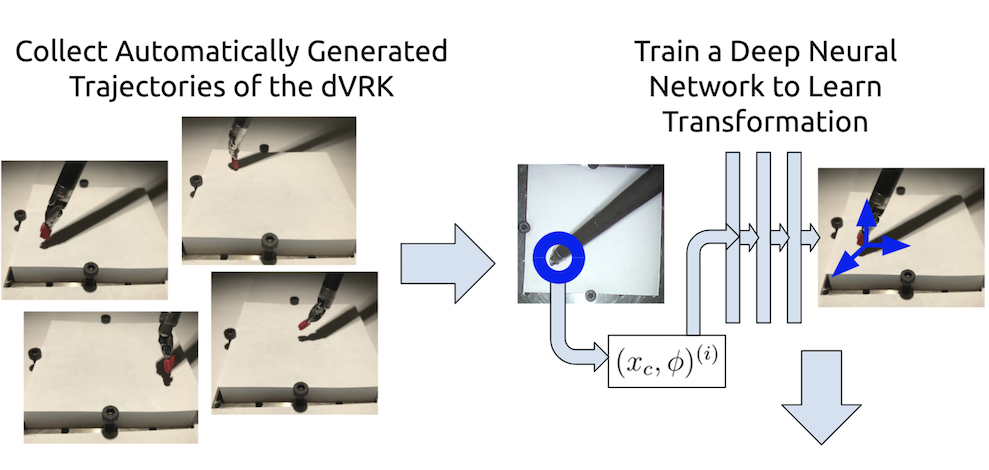
Fast and Reliable Autonomous Surgical Debridement with Cable-Driven Robots Using a Two-Phase Calibration Procedure
Daniel Seita, Sanjay Krishnan, Roy Fox, Stephen McKinley, John Canny, Ken Goldberg
@inproceedings{seita_icra_2018,
title = {{Fast and Reliable Autonomous Surgical Debridement with Cable-Driven Robots Using a Two-Phase Calibration Procedure}},
author = {Daniel Seita and Sanjay Krishnan and Roy Fox and Stephen McKinley and John Canny and Kenneth Goldberg},
booktitle = {IEEE International Conference on Robotics and Automation (ICRA)},
Year = {2018}
}
Automating precision subtasks such as debridement (removing dead or diseased tissue fragments) with Robotic Surgical Assistants (RSAs) such as the da Vinci Research Kit (dVRK) is challenging due to inherent non-linearities in cable-driven systems. We propose and evaluate a novel two-phase coarse-to-fine calibration method. In Phase I (coarse), we place a red calibration marker on the end effector and let it randomly move through a set of open-loop trajectories to obtain a large sample set of camera pixels and internal robot end-effector configurations. This coarse data is then used to train a Deep Neural Network (DNN) to learn the coarse transformation bias. In Phase II (fine), the bias from Phase I is applied to move the end-effector toward a small set of specific target points on a printed sheet. For each target, a human operator manually adjusts the end-effector position by direct contact (not through teleoperation) and the residual compensation bias is recorded. This fine data is then used to train a Random Forest (RF) to learn the fine transformation bias. Subsequent experiments suggest that without calibration, position errors average 4.55mm. Phase I can reduce average error to 2.14mm and the combination of Phase I and Phase II can reduces average error to 1.08mm. We apply these results to debridement of raisins and pumpkin seeds as fragment phantoms. Using an endoscopic stereo camera with standard edge detection, experiments with 120 trials achieved average success rates of 94.5%, exceeding prior results with much larger fragments (89.4%) and achieving a speedup of 2.1x, decreasing time per fragment from 15.8 seconds to 7.3 seconds.
International Conference on Robotics and Automation (ICRA), 2018
|
|
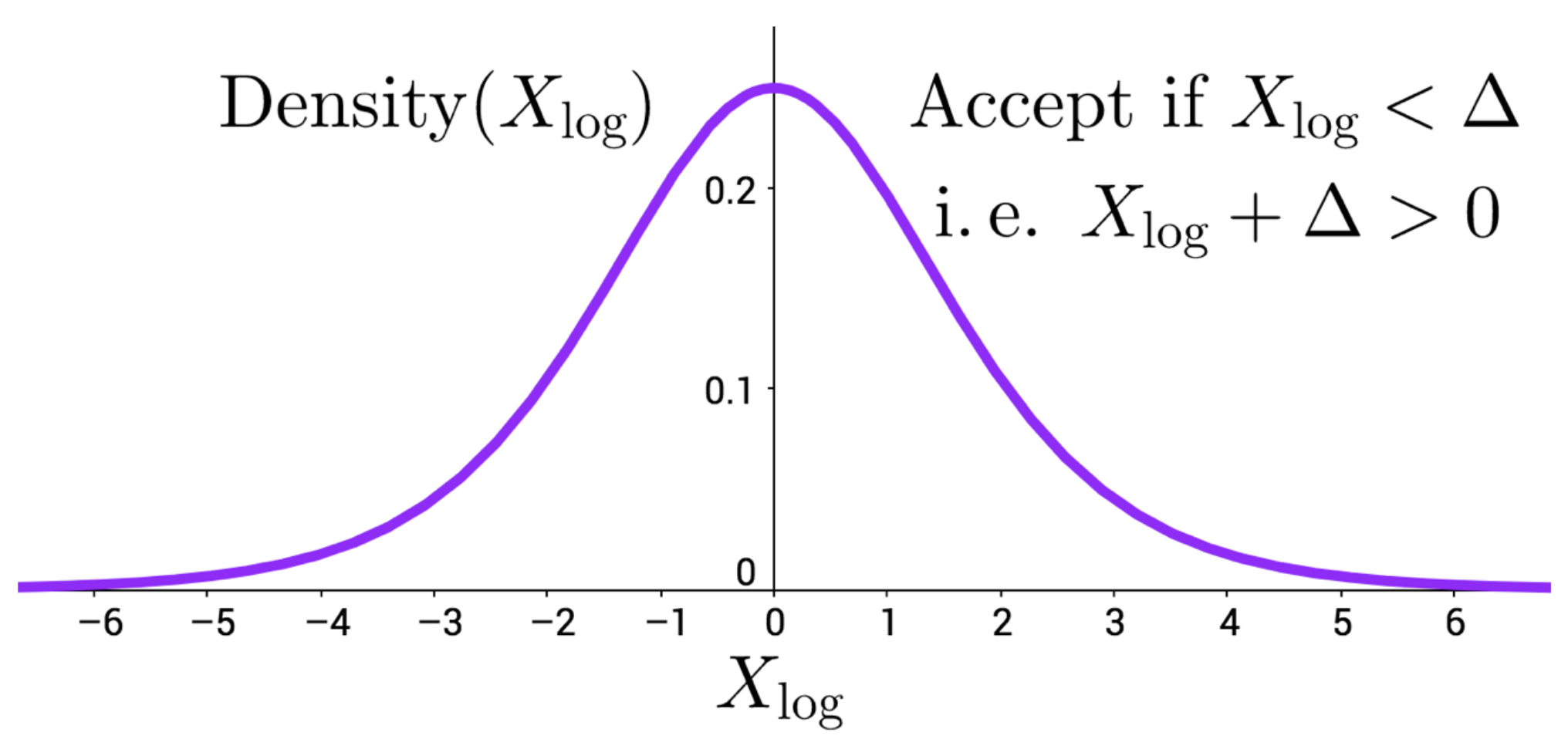
An Efficient Minibatch Acceptance Test for Metropolis-Hastings
Daniel Seita, Xinlei Pan, Haoyu Chen, John Canny
@inproceedings{seita_uai_2017,
title = {{An Efficient Minibatch Acceptance Test for Metropolis-Hastings}},
author = {Seita, Daniel and Pan, Xinlei and Chen, Haoyu and Canny, John},
booktitle = {Conference on Uncertainty in Artificial Intelligence (UAI)},
year = {2017}
}
We present a novel Metropolis-Hastings method for large datasets that uses small expected-size minibatches of data. Previous work on reducing the cost of Metropolis-Hastings tests yield variable data consumed per sample, with only constant factor reductions versus using the full dataset for each sample. Here we present a method that can be tuned to provide arbitrarily small batch sizes, by adjusting either proposal step size or temperature. Our test uses the noise-tolerant Barker acceptance test with a novel additive correction variable. The resulting test has similar cost to a normal SGD update. Our experiments demonstrate several order-of-magnitude speedups over previous work.
Uncertainty in Artificial Intelligence (UAI), 2017 - Honorable Mention for Best Student Paper
|

|
Large-Scale Supervised Learning of the Grasp Robustness of Surface Patch Pairs
Daniel Seita, Florian T. Pokorny, Jeffrey Mahler, Danica Kragic, Michael Franklin, John Canny, Ken Goldberg
@inproceedings{seita_simpar_2016,
title = {{Large-Scale Supervised Learning of the Grasp Robustness of Surface Patch Pairs}},
author = {Daniel Seita and Florian T. Pokorny and Jeffrey Mahler and Danica Kragic and Michael Franklin and John Canny and Ken Goldberg},
booktitle = {IEEE International Conference on Simulation, Modeling, and Programming for Autonomous Robots (SIMPAR)},
Year = {2016}
}
The robustness of a parallel-jaw grasp can be estimated by Monte Carlo sampling of perturbations in pose and friction but this is not computationally efficient. As an alternative, we consider fast methods using large-scale supervised learning, where the input is a description of a local surface patch at each of two contact points. We train and test with disjoint subsets of a corpus of 1.66 million grasps where robustness is estimated by Monte Carlo sampling using Dex-Net 1.0. We use the BIDMach machine learning toolkit to compare the performance of two supervised learning methods: Random Forests and Deep Learning. We find that both of these methods learn to estimate grasp robustness fairly reliably in terms of Mean Absolute Error (MAE) and ROC Area Under Curve (AUC) on a held-out test set. Speedups over Monte Carlo sampling are approximately 7500x for Random Forests and 1500x for Deep Learning.
International Conference on Simulation, Modeling, and Programming for Autonomous Robots (SIMPAR), 2016
|
